Diver OSINT CTF 2025 writeup
Diver OSINT CTF 2025 にソロで参加してみました。
結果としては45位でした。

最後の一歩詰め切れなかった問題もあったりして悔しい印象です。あとさすがに時間が足りない。
なお、このwriteupは、運営の方よりアナウンスされた次のルールを遵守しています。
以下の問題に対するwriteupでは、必ず個人の氏名や顔写真をマスクしてください(解法は記述してかまいません)
document (introduction),
bid (comany),
worker (military),
以下の問題の添付ファイルを記載する場合、必ず以下の出典を記載してください
listen
- LiveATC CYEG-Del-Gnd-Misc-Jan-18-2025-0500Z,
以下の問題で登場したこれらの人物は、CTFのために作成されたアカウントなので、言及してかまいません。ただし、これらの人物以外のアカウントがあれば、ユーザ名やアイコン、メールアドレスなどを絶対にマスクしてください。不明な点はチケットで問い合わせてください。
Mizuki Sekozaki (mizuki1206edelweiss),
Shinonome Kodai (kodai_sn, shinonomekodai),
Makoto Uchigashima (makoto.u.sunflower),
Temari Izuhara (izuhara.calla.lily, callalily-izuhara)
Introduction
bx [100 pts, 469 solves]
この写真で見える "BX" という看板の座標を答えなさい。 Give the coordinates of the "BX" signboard visible in this picture.
(地図上でピンを刺す回答方式)

看板を切り抜いて「文化シヤッター」の文字とともにGoogle Lens すると、TikTok公式アカウントの投稿が出てくる。
上野駅と鶯谷駅の間にあることがわかるので、Google Mapから探して解答。
document [100 pts, 280 solves]
この問題のwriteupは、「必ず個人の氏名や顔写真をマスクしてください」というルールを遵守して記述されています。
アメリカ海軍横須賀基地司令部(CFAY)は、米軍の関係者向けに羽田空港・成田空港と基地の間でシャトルバスを運行している。2023年に乗り場案内の書類を作成した人物の名前を答えよ。
「CFAY shuttle bus」あたりで検索をかけると、この資料が引っかかる。下部に
"Title" (画面上部の黒帯に出てくるやつ)に C:\Users\[USERNAME]\AppData\Local\Temp\1\msoF678.tmp みたいな文字列が含まれていた。ただ、[USERNAME]が直接本名になりそうではない(George Washington なら Geo.Wash みたいな感じ)。そこで、メタデータの抽出を思いつく。
"PDF metadata extractor" で出てくるこのサイトに放り込むとAuthorが表示されてしまっているので、それをsubmit.
finding_my_way [100 pts, 408 solves]
34.735639, 138.994950 にある 建造物 の、OpenStreetMapにおけるWay(ウェイ)番号を答えよ。 Flag形式: Diver25{123456789}
Answer the Way number in OpenStreetMap of the building located at 34.735639, 138.994950. Flag Format: Diver25{123456789}
ヒント: 「建造物」は「地物」の一種である / a "building" is categorized into "features"
指定された地点は、伊豆半島の天嶺山に上る途中の道にある建物。
OpenStreetMapで確認すると、やはり同じ場所に建造物がある。
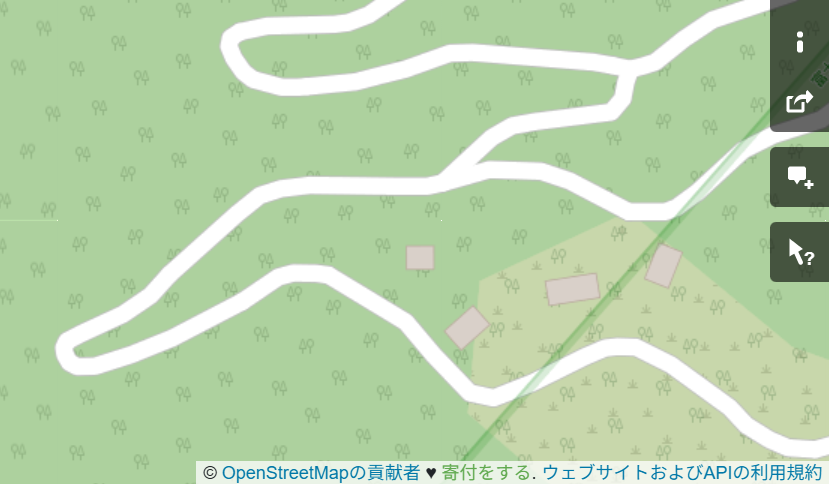
ツールバーに「地物を検索」というメニューがあるので、ヒントにある通りこれで詳細を見られるのだろう。
実際やってみると、ウェイ番号がきちんと表示されるので、これをsubmit.
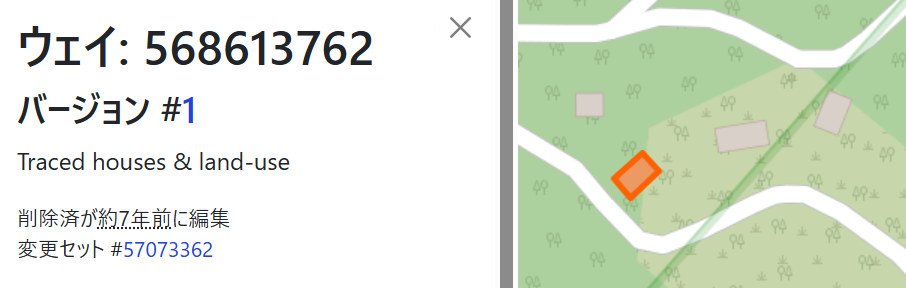
誘導がめちゃくちゃしっかりしていて助かる。
flight_from [100 pts, 362 solves]
このヘリコプターが出発した飛行場のICAOコード(4レターコード)で答えよ。 Flag形式: Diver25{RJTT}
ヒント:データを入念に確認してください。あなたのOSINT能力を期待しています。 / Confirm the data carefully. We expect your OSINT ability.
(5 attempts)
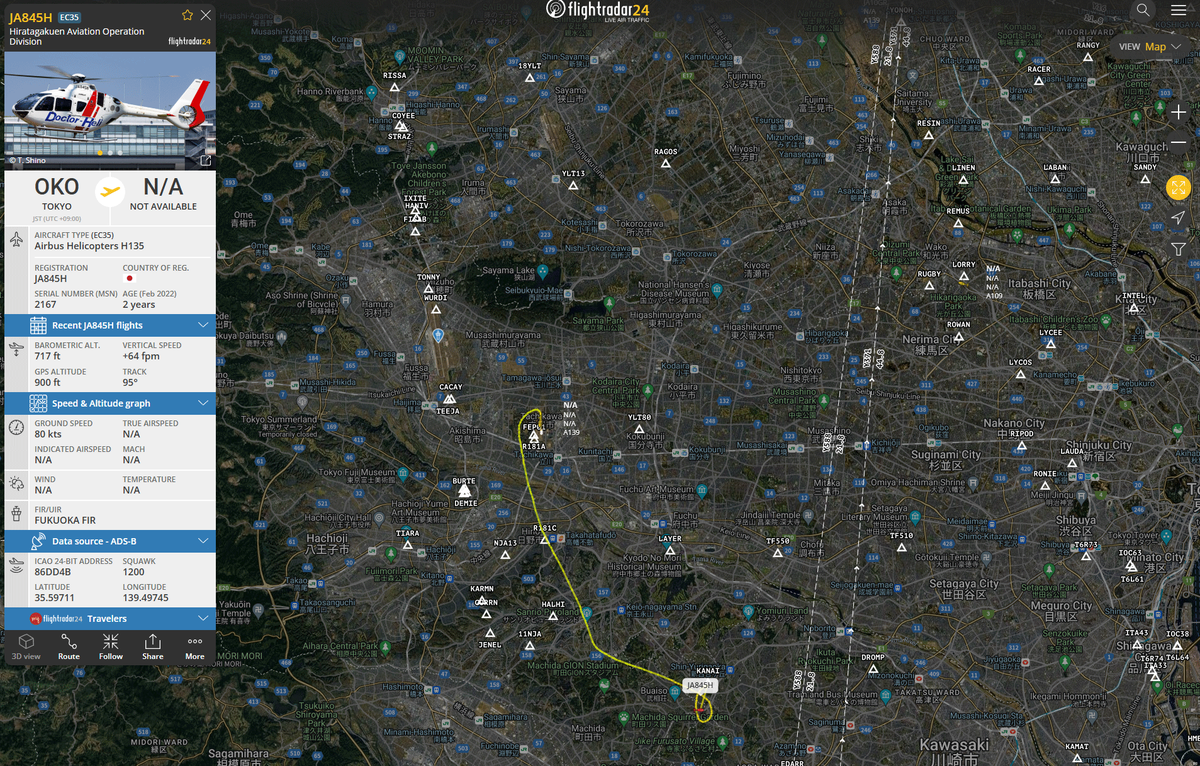
画像を見るとOKO(横田飛行場)となっているが、Wikipediaに乗っている横田飛行場の4レターコードであるRJTYをそのまま入れて通るほど甘くはないだろう。
Google Mapで画像を拡大して見ると、出発地が陸上自衛隊立川駐屯地であることがわかる。
WikipediaにあるIACOコードの RJTC が答え。
hidden service [100 pts, 354 solves]
添付ファイルを確認して、Flagを獲得してください!
ヒント:ルールに記載しているとおり、このCTFでは違法なサービスを利用する必要はありません(合法性の判断は日本国の法令に準拠します)。

Tor browser をダウンロードしてURLを書き起こして打ち込む。
ship [100 pts, 363 solves]
これは、ある組織が運用する船舶である。もし将来、この船が外国に売却されたとしても、変わらない番号を答えよ。 Flag形式: Diver25{現地語での船名_番号}(例: 船名が「ペンギン饅頭号」で番号が 1234567 の場合、Flagは Diver25{ペンギン饅頭号_1234567} となる)
ヒント:船名には記号を含まない。 / The ship name doesn't contain symbols.
(15 attempts)

隠れているが「7JVV」 という文字が読み取れるので、これを検索すると神鷹丸*1という船の信号符字が7JVVであることがわかる。
信号符字の下にIMO番号なるものがあるので、IMO番号についての説明を読む。Wikipediaによると、
船舶に与えられたIMO番号は廃船になるまで変更されることがなく、所有者や船籍が変更されたとしても変更されない。
とのことなので、これをsubmitすればよさそうだ。ちなみに、信号符字の2個下にあったMMSI番号というものは「構成する数字9桁の最初の3桁は国を示す」ということで、おそらく外国に売却されると変更されるだろう。
louvre [176 pts, 181 solves]
ルーブル美術館の公共Wi-Fiアクセスポイントのうち、以下の条件を満たすもののベンダーを答えよ。
- 情報は2025年2月28日に収集されており、オンライン上で確認できる。
- ベンダーはBSSIDに準拠して判定せよ。
Flag形式: Diver25{Company Name} (例: Apple Inc.の場合、Diver25{Apple Inc.} となる。)
ヒント:Wi-Fiアクセスポイントに関して、有名なサイトがあるはずです。 / There should be a well-known website on Wi-Fi access points.
ヒント:BSSIDの仕様について調べてみましょう。 /Find out about the BSSID specifications.
「Wi-Fiアクセスポイントに関して、有名なサイト」とは何だろうか。知らなかったので「wifi access point database」でググるとWiGLEが出てくる。
使い方があまりよくわからないまま、マップ画面でウロチョロしてたらDaily Limitが来て、「詰んだか?」と思ったが、どうやらAdvance Search は使えるらしい。Advance Search では SSID と Last Updated などを指定して検索できるらしい。マップ見なくても最初からこれでよかった。
"musee du louvre wifi" で検索して出てくる公式サイトの情報からSSIDが ‘Louvre_Wifi_Gratuit’ であることがわかる。Last Updated に2025年2月28日を指定すると、2/28に登録されたBSSIDが2件出てくる。
ところでベンダーはどうやったらわかるか。ググると、BSSIDはだいたいMACアドレスと一致するらしく、その前半6桁がベンダーコードとのこと。MACアドレスからベンダーを逆引きできるサイトがあったので、これを使えばベンダーの名前がわかる。
p2t [377 pts, 112 solves]
この写真の左側に掲示されている写真には、ある動物が写っている。その名前を、日本語で書かれている通りに答えよ。
Flag 形式: Diver25{シバイヌ}

何らかの博物館や資料館的なものの展示だろう。「ハシブトガラス 立山」で検索すると「立山自然保護センター」がひっかかる。
「立山自然保護センター ハシブトガラス」で画像検索すると、詳細な画像を上げてくれているサイトが引っかかる。これを見れば左にトビが映っていることがわかる。
geo
Afghanistan [414 pts, 94 solves]
動画 / Video: https://www.youtube.com/watch?v=NWQwx4-MeRg&t=65s
この動画の65~67秒に表示される写真はいつどこで撮影されたものか。
Flag形式: Diver25{撮影場所名_YYYY-MM-DD}(撮影場所名は英語)
例えば、2025年6月5日に、Camp Darbyで撮られた場合は、Diver25{Camp Darby_2025-06-05}となる。
(地図上でピンを刺す回答方式)
(15 attempts)
タイトル「Afghanistan, 2009 : a year both deadly and decisive」で検索を掛けても不発。画像検索もそれらしきものは引っかからない。
そこでふと、AFP News の報道写真ライブラリのようなものがないかと思いつく。"afp news photos library" で検索するとビンゴ。
"afghanistan basketball military" で検索すると無事引っかかる。説明文を読むと、撮影地はCamp Bostick、撮影日時は2009-04-16であることがわかる。
night_street [428 pts, 86 solves]
画像の中心に写っている茶色の2階建ての建物に入る施設の正式名称を現地語表記で答えなさい。
Flag形式: Diver25{施設名}(例: Diver25{お台場海浜公園前郵便局})
注意: この問題を解く際、外部サイトへの機械的なアクセスやスクレイピングは禁止します。また、それらを行う必要はありません。 ただし、ブラウザから手動で取得できる情報や、公開されているAPIサービスやデータセットの利用は問題ありません。
ヒント:The church-like building on the left is apparently a Japanese restaurant chain.

方針1.OpenStreetMapによる探索
画像左の建物はリンガーハットだろう。そこで、ChatGPTにOverpass Turbo*3のクエリを書かせる。
overpass turbo で、
名前に「クリニック」がつく建物
名前に「リンガーハット」がつく建物
が隣接している、という条件はどうやって書く?
何ターンかの修正*4を経て次のコードに落ち着く。
[out:json][timeout:25]; // 「クリニック」を含む建物 ( nwr["name"~"クリニック"]["building"]; )->.clinics; // その周囲50m以内にある「リンガーハット」を含む建物 ( nwr["name"~"リンガーハット"]["building"](around.clinics:50); )->.ringhats; // 両者を表示(※ clinics はそのまま表示) ( .clinics; .ringhats; ); out center;
……実行するが、どうも実行時のメモリ上限2048MBをオーバーしたようだ。そもそも ( nwr["name"~"クリニック"]["building"];)->.clinics; だけでもオーバーする。
アプローチを変えて聞いてみる。新規チャットを開き、
overpass turbo で、リンガーハットを全件検索するには?
と聞く。その結果を踏まえ、
その近くにある病院を検索するには?
と聞く。これが返ってくる。
[out:json][timeout:30]; // ステップ1: リンガーハットの位置を取得 ( node["name"~"リンガーハット"]; node["brand"~"リンガーハット"]; node["operator"~"リンガーハット"]; )->.lh; // ステップ2: リンガーハットの周囲500m以内の病院を検索 ( node["amenity"="hospital"](around.lh:500); way["amenity"="hospital"](around.lh:500); relation["amenity"="hospital"](around.lh:500); ); out center;
50mに修正して実行。今度はうまくいくも、それっぽい結果が出てこない。ということは、OpenStreetMapに登録されていないリンガーハットが答えなのではないか。
方針2.目視による全探索
覚悟を決めて、手動全探索に移る。すなわち、リンガーハット公式HPの店舗一覧から全店舗の名前が調べられるので、564軒すべてのリンガーハットのストリートビューを閲覧し、問題の画像に当てはまるものを探す。
ただし、このリンガーハットは1戸建て*5である。住所が「北海道札幌市東区北7条東9丁目2-20 アリオ札幌2Fフードコート」のようなものは見なくてよい。幸いなことにリンガーハットは結構な割合でショッピングセンターの中にあるので、探索にかかる時間はある程度は削減される。
北海道・東北、北陸、関西、四国あたりは(兵庫17店舗、大阪25店舗を除けば)どの県も店舗数は1桁なのでまだよい。イオンなどフードコート率も高い。問題は関東である。
- 東京(76店舗):Not Found
- 千葉(41店舗):Not Found
- 埼玉(49店舗):Not Found
- 神奈川(63店舗):Not Found
栃木、茨城、群馬はどれも店舗数1桁で、見つからないことが容易にわかる。この時点で、去年のDiver OSINT にあった(ネタバレ回避のため白字)「ビルの4Fにある鳥貴族の電話番号を答えよ(答えとなる鳥貴族は実は閉店済み)」が頭によぎる。
結局答えは愛知県にあり、リンガーハット 名古屋弥富通店の隣にある「弥富通クリニック」であった。
おそらく500件近くのリンガーハットの住所情報を閲覧し、100件~200件程度の外観を見ることとなった。とてもつかれた。
what3slashes [446 pts, 75 solves]
この画像が撮影されたとき、正面に家が3軒、右手に家が1軒あった。
それから少し経った、ある月の初旬にこの場所にもう一度訪れてみた。そのときには、正面左側に家が1軒増えていて、正面右側にもう1軒が建設中であった。その時点で、建設中の家に屋根はなかったが、黒っぽい屋根を作る予定だという。
「ある月の初旬」とは何年の何月のことだろうか。
Flag形式 : Diver25{YYYY/MM} (e.g. Diver25{2025/06})
(5 attempts)

どうみてもWhat3words. GeminiとGoogle Lens に文字起こしさせて、これがモンゴル郵便のサービスであることと、アドレス Бунба.Цогу.Батмагaв がわかる。ということで、what3wordsの設定をモンゴル語(キリル文字)に切り替えて、当該アドレスの場所を見てGoogle Mapに飛ぶ。過去の情報を抽出するのでストリートビューのタイムラプスだろうと思いきや、なんとストリートビューそのものがない。
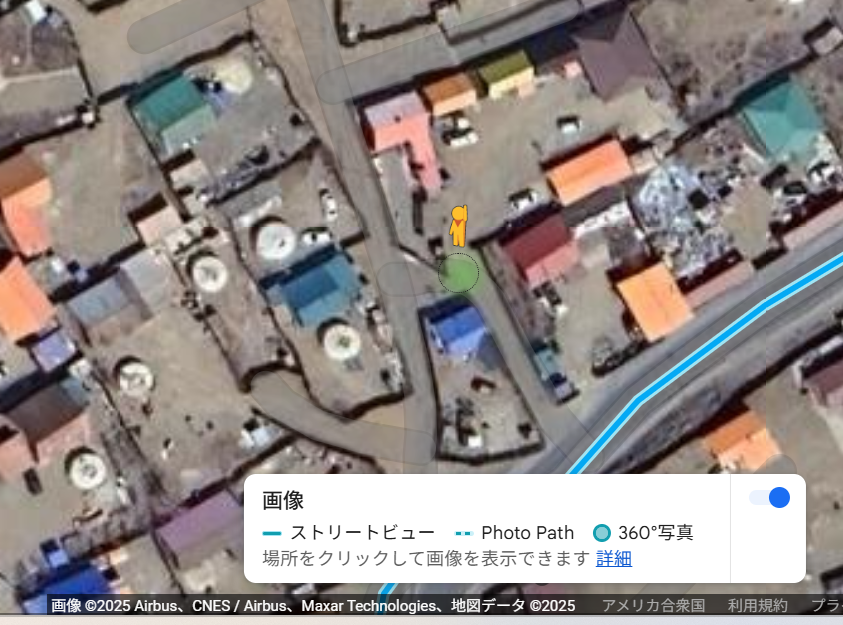
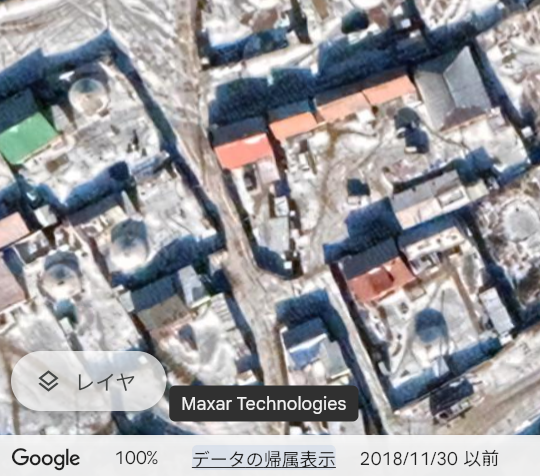
ということで過去の衛星画像を見るしかない。「satellite image in the past」でググって探すと、Google Earthが提供していることがわかった。

convenience [462 pts, 63 solves]
青森県内に、公園とコンビニ、スーパーマーケットが互いに約100m圏内に存在する場所がいくつかある。また、これはOpenStreetMapで確認可能である。
この条件を満たす 公園 のうち、最南端 のものについて、OpenStreetMap上での Way Number を答えよ。
なお、「公園」の定義は、OpenStreetMap上で "park" (leisure=park) と分類されているものに準拠する。
Flag形式: Diver25{123456789}
(7 attempts)
ChatGPTにOverpass Turbo のクエリを書いてもらおうとした。
青森県内の、公園とコンビニ、スーパーマーケットが互いに約100m圏内に存在する場所を出力するOverpass turboクエリを書いて
答えは次の通り。
[out:json][timeout:60];
// 青森県の境界を取得
area["name"="青森県"]["admin_level"="4"]->.a;
// 公園を取得
(
node["leisure"="park"](area.a);
way["leisure"="park"](area.a);
relation["leisure"="park"](area.a);
)->.parks;
// 各公園の周囲100m以内のコンビニとスーパーを検索
foreach .parks -> .p (
// 100m以内のコンビニ
(
node(around.p:100)["shop"="convenience"];
way(around.p:100)["shop"="convenience"];
relation(around.p:100)["shop"="convenience"];
)->.convs;
// 100m以内のスーパー
(
node(around.p:100)["shop"="supermarket"];
way(around.p:100)["shop"="supermarket"];
relation(around.p:100)["shop"="supermarket"];
)->.supers;
// 公園・コンビニ・スーパーすべてが存在する場合に出力
(
.p;
.convs;
.supers;
) if (.convs.count > 0 && .supers.count > 0);
);
まずif文でエラーを吐く。「エラー吐いたんだけど」って言ったら、supersの定義以降を次の通り修正した。
// 公園の近く(100m)にあるコンビニ node(around:100, .parks)["shop"="convenience"]->.near_convs; // 公園の近く(100m)にあるスーパー node(around:100, .parks)["shop"="supermarket"]->.near_supers; // それぞれの施設の近くに他の2施設がある公園を抽出(交差) node(around:100, .near_convs)["leisure"="park"]->.parks_with_convs; node(around:100, .near_supers)["leisure"="park"]->.parks_with_supers; // コンビニとスーパー両方が近くにある公園を抽出(交差) node.parks_with_convs.parks_with_supers->.target_parks; // 最終的に公園・コンビニ・スーパーを出力 ( node.target_parks; node(around:100, node.target_parks)["shop"="convenience"]; node(around:100, node.target_parks)["shop"="supermarket"]; ); out center;
これも使えない。諦めて自力でコードを書く*6。
方針としては、「公園全体を取得→コンビニのうち、公園の100m圏内にあるものを取得→スーパーのうち、それらのコンビニの100m圏内にあるものを取得」とする。
[out:json][timeout:60]; // 青森県のエリア取得 area["name"="青森県"]["admin_level"="4"]->.a; // 公園を取得 ( node["leisure"="park"](area.a); way["leisure"="park"](area.a); relation["leisure"="park"](area.a); )->.parks; // コンビニを取得 ( node["shop"="convenience"](around.parks:100); way["shop"="convenience"](around.parks:100); relation["shop"="convenience"](around.parks:100); )->.convs; // スーパーを取得 ( node["shop"="supermarket"](around.convs:100); way["shop"="supermarket"](around.convs:100); relation["shop"="supermarket"](around.convs:100); ); our center;
これは動く。
ただし、問題の条件を満たすならば必ずこのクエリには引っかかるが、このクエリに引っかかるものがすべて問題の条件を満たすとは限らない*7ため、出てきた最南端のものが本当に問題の条件を満たすかの検証が必要。
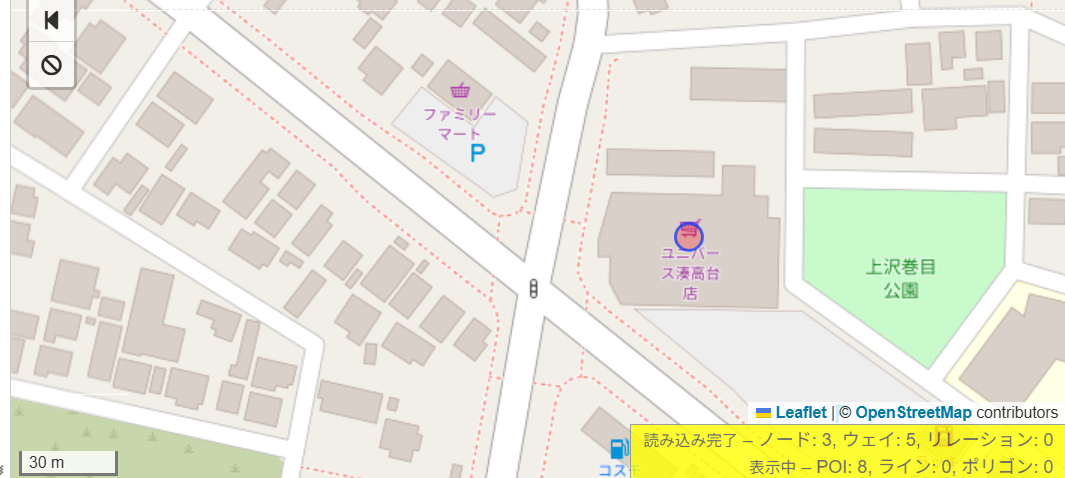
たぶんそれぞれ100m圏内なのでOK。この公園のウェイ番号をsubmit.
advertisement [100 pts, 233 solves](解けなかった)
記事 / Article:
この記事の写真が撮影された場所はどこか。
(地図上でピンを刺す回答方式)
(5 attempts)
ロシア軍の勧誘の看板らしい。
看板の下には「ТОКИО-CITY」(TOKYO-CITY)というレストランチェーンのロゴが見える。その下には、よく見ると OQ という印刷会社のロゴも見える。また、バーガーキングの宣伝も見える。
OQ Express の位置を総当たりしようとして心が折れたが、今思えば(リンガーハットよりは)少ないので普通にできたな……
hole [449 pts, 72 solves] (解けなかった)
この穴があった場所はどこか。
(地図上でピンを刺す回答方式)
(5 attempts)

とりあえずGoogle Lens すると、 BYD の車が穴を飛び越える機能を搭載、という旨の記事が見つかる。画像と完全一致する動画も見つかる。この動画から、この道路が山西省大同市にあることがわかる。

そこから、Baidu で大同汽车试验场などと検索するも不発。飛行場っぽい?と思い大同の空港を調べるも、出てくる大同雲崗空港は合っていそうにない*8。
最終的にそれっぽい地形を航空写真で全探索しようとしたが、1/3くらい見たところで心が折れて諦めてしまった。後で他のチームのWriteupを読んだら、全探索で見つけたチームもあったらしく、𝑃𝑂𝑊𝐸𝑅の不足を感じた。
Talentopolis [472 pts, 53 solves](解けなかった)
記事 / Article:
https://www.guineaecuatorialpress.com/noticias/primera_edicion_de_talentopoli
"Primera edición de Talentopolis" という記事内に登場するステージの位置を答えよ。
(地図上でピンを刺す回答方式)
(5 attempts)
記事曰く、Malabo の barrio de San Juan で行われたイベントらしい。その位置をググってみる。
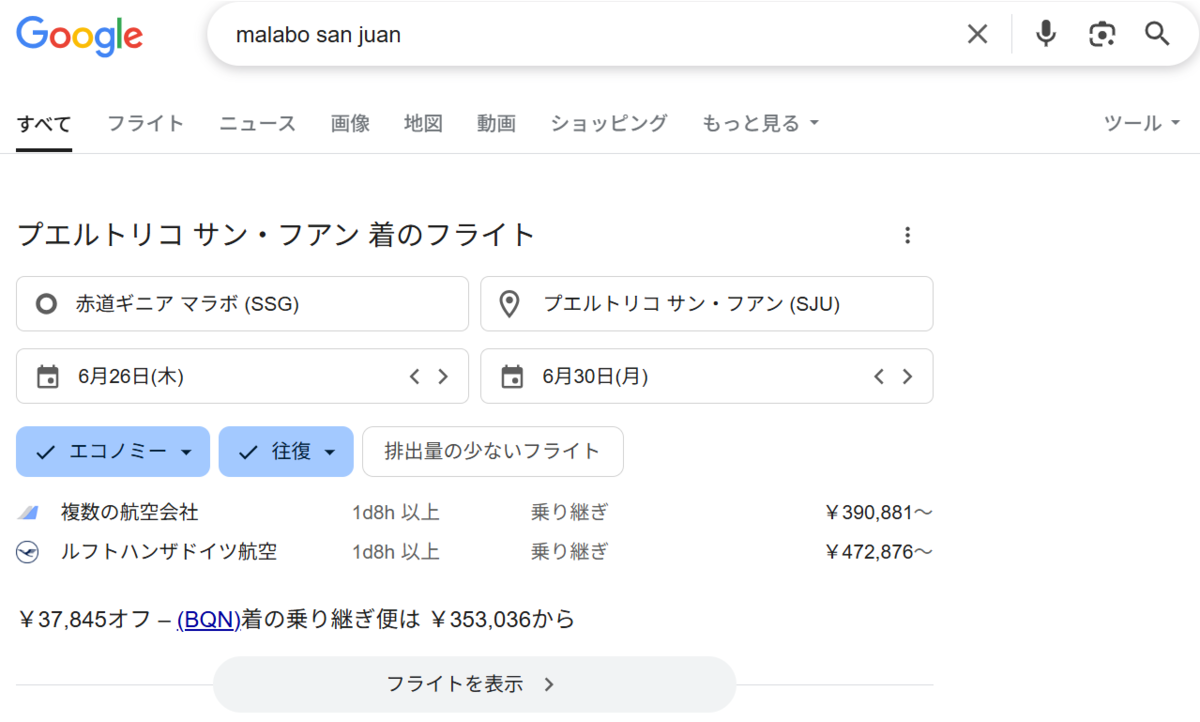
MalaboからプエルトリコのSan Juan への航空情報が出てきてしまう。
その後の過程はあまり覚えていないが、いくつかの記事の画像からステージ周辺の様子がわかる。これらより、
- ステージが何らかの細長い建物の短辺の側にあること
- 左奥にはまた細長い建物があること
- 右奥には屋根が黒い建物があること
- ステージ手前には駐車場があること
などがわかる。
また、malabo san juan barrio でググると出てくるこの記事からAfri Mallなる施設が San Juan にあることがわかる。
Afri Mall の位置はGoogle Mapで出てくるので、衛星写真からその周辺を探すと、ちょうどAfri Mallの右にそれっぽい建物がある。それ以外にそれっぽい建物はない。
ただ、どの棟が答えになるのかがわからなかった。特に「屋根が黒い」という条件に引っかかって答えを導けなかった。
recon
00_engineer [100 pts, 346 solves]
東京駅の近くでソフトウェアエンジニアの名札を拾った。おそらく落とし物だろう。
このエンジニアが勤務している会社のWebサイト(トップページ)のURLを答えよ。
Flag 形式: Diver25{https://google.com}
recon カテゴリの問題を解答するには、この問題の情報が必要となる。ただし、この問題を除き、どの順序で解答しても構わない。
ヒント:この名札が東京駅近くで見つかったことから、日本の会社だろう。 / This should be Japanese company because this nameplate was found nearby Tokyo Station, Tokyo, Japan.
(10 attempts)

kodai_snでGoogle検索を掛けてみたが、見つからない。 エンジニアだろうからgithubでもkodai_snを見てみるが、やはり見つからない。
ふと思いついて、https://x.com/kodai_snを見てみると、これにはヒットした。 ツイートに会社名書いてないかなーと思ったが、それらしきものは見つからない。
ふとbioを見ると、kodai-sn.github.io へのリンクがあった。ここにMagneight Softwareで働いている、という旨の記述がある。これをググると会社のホームページが出てきた。
Diver25{https://magneight.com}
03_ceo [302 pts, 142 solves]
"00_engineer" の問題で見つかった会社の、CEOのメールアドレス(Gmail)を答えよ。
Flag 形式 / Flag Format: Diver25{example@gmail.com}
(5 attempts)
MagneightのホームページによるとCEOは Sekozaki Mizuki らしい。
ツイートに、「CEOがgitハンズオンをやってくれた」という記述がある。
リリースが一段落したので、gitハンズオンを我が社のCEOもやってくれたらしい。
— Kodai.S (@kodai_sn) 2025年4月22日
社内のドキュメントをMarkdownに一本化するのも不可能ではないかもしれないな。
また、そのハンズオンの資料がspeakerdeckに上がっているとのこと。
週明け、社内向けにgitとGitHubのハンズオンをやろうと思う。
— Kodai.S (@kodai_sn) 2025年3月1日
パワフルなツールなのだから、エンジニアではないメンバーにも活用して欲しいと思っている。https://t.co/JeVKEjmbj0
この資料では、リポジトリを作る練習をしている。ご丁寧に「今回は機密情報を保存しないのでPublicで良いでしょう」と書いてある。ということは、kodai-sn のリポジトリと同じ文言を含むリポジトリがどこかにあるのではないか。
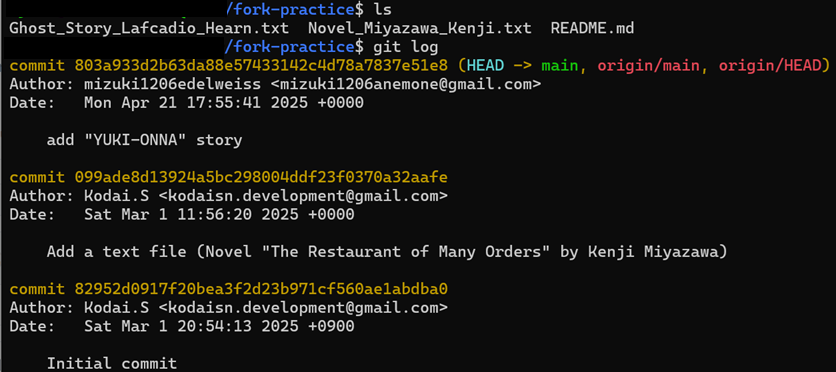
前問から、kodai_snのgithubアカウントの名前がkodai-snであることがわかり、https://github.com/kodai-snにアクセスする。とりあえず kodai-sn/practice にある"The repository for my git practice!"という文字列でGithubの全体を検索すると、mizuki1206edelweiss/practice が引っかかる。これだ。
メールアドレスに関しては、そういえば git log するとメールアドレスがわかったな、というのを思い出し実行する。
これをsubmit.
02_recruit [488 pts, 37 solves]
"00_engineer" の問題で見つかった会社で、採用を担当していると思われる人物の氏名を答えよ。
Flag 形式: Diver25{Shigeru Ishiba} (ローマ字表記)
(3 attempts)
Magneightのホームページの[Contactのページ]に、
Careers
Currently, we don't have open positions.
とある。ということは、過去には募集していたのではないか。
webページの過去バージョンといえば archive.today である。magneight.comのアーカイブを検索すると、4/10の版が残っている。
Careers
We are hiring! The details of open position(s) are here.
とのことである。リンク先はGoogleドキュメントとなっている。
実はGoogleドキュメントのオーナーは、ドライブの「最近使用したアイテム」などから見ることができる。
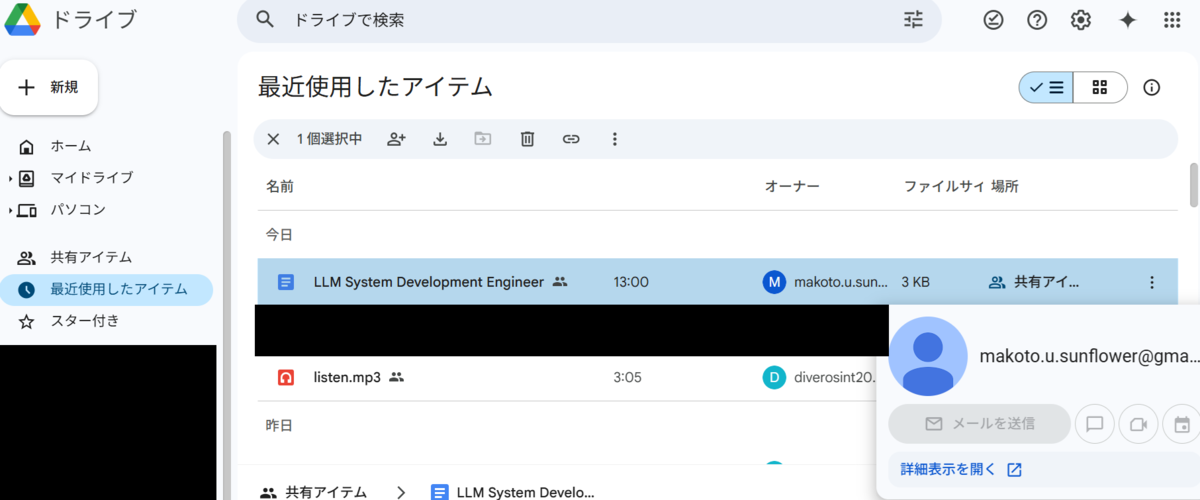
ということでGhunt*9に放り込むと、レビューの一覧ページが出てくる。ここに名前が書いてあった。
transportation
next_train [100 pts, 245 solves]
この音声が録音された駅はどこか。駅名を答えよ(日本語でも英語でも可)。
(駅名は鉄道会社の公式サイトやWikipediaに記載されている表記とする)
Flag形式: Diver25{京都駅}
(3 attempts)
音声からは、
(00:42) 15番線の電車は、14時16分発、普通、久里浜行きです。
と聞こえる。「15番線」はちょっと怪しかったが、00:58あたりに「track number 15」と言っているのが聞こえたので、とりあえず確定させる。
「久里浜行き」でググると、この電車がJR横須賀線であることがわかる。
15番線までありそうなのは、東京、品川、横浜くらいだろうと見当はつく。実際、時刻表を探すと品川14:16着・発の電車がある。
3 attempts なので慎重に調査するため、「横須賀線 ホーム」でググって出てきた横須賀線の各駅の停車ホームを一覧にしているサイトを総当たりして、横須賀線が15番線に停車するのが品川だけであることを確かめる。大丈夫そうだ。
platform [136 pts, 192 solves]
この写真が撮影された駅はどこか。駅名を答えよ(日本語でも英語でも可)。
(駅名は鉄道会社の公式サイトやWikipediaに記載されている表記とする)
Flag形式: Diver25{京都駅}
(10 attempts)

「10両9号車乗車口」の色から中央線とかかなーと推測する。実際、「JR 6両 10両」でググると出てくる、電車の編成一覧に、「中央快速線・中央線・青梅線・五日市線」に6両編成の電車が走っていることが記載されている。
一方、写真には「らいと」というお店が映っている。そこで、GoogleMapで、中央線の東京市部あたりにフォーカスを合わせて「らいと」を検索してみる。
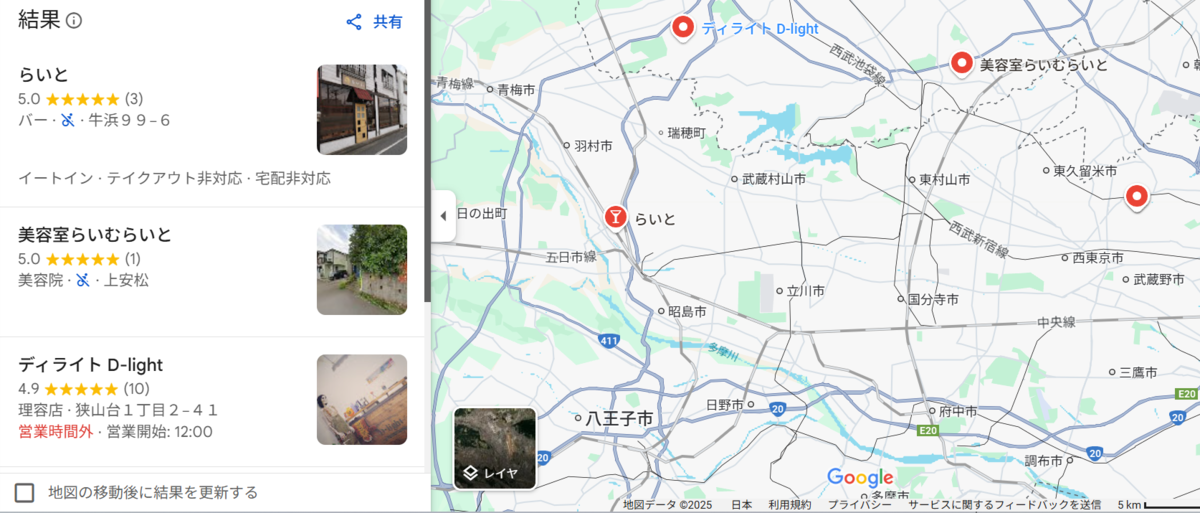
無事見つかった。外観もそのままだし、ストリートビューを見るとその隣の店の外観とも一致する。したがって答えは「牛浜駅」である。
air2air [495 pts, 24 solves]
動画 / Video:
https://www.youtube.com/watch?v=wUa5TGj6uxc
(無音です / No audio)
この動画は2025年3月11日(現地時間)に撮影された。遠くに映っている航空機のコールサインと機体記号を答えよ。
(撮影者が搭乗している航空機ではない)
Flag形式: Diver25{コールサイン_機体記号}(例: Diver25{ANA0183_JA381A})
ヒント:有料の情報源を使う必要はない。
飛行機から外を見ると、進行方向左側にもう一つ飛行機が見える、という状況。
2025年3月11日の飛行機についての情報なので、過去問のwriteupで出てきた, 飛行機の過去の情報が見られる ADS-B Exchange が思い浮かぶ。
ということで、まず乗っている飛行機についての情報を集める。
0:16あたりに映っている、翼の先端のマークが特徴的である。

この部分はウィングレットというらしい。Googleレンズに掛けると、おそらくスターラックス航空であろうことがわかる。
また、動画の最後に映っている飛行機の現在地の情報を見ると、
- 沖縄の北あたりを飛んでいること
- 台湾の TPE に向かっていること
がわかる。TPEとは台湾桃園国際空港のことらしい。
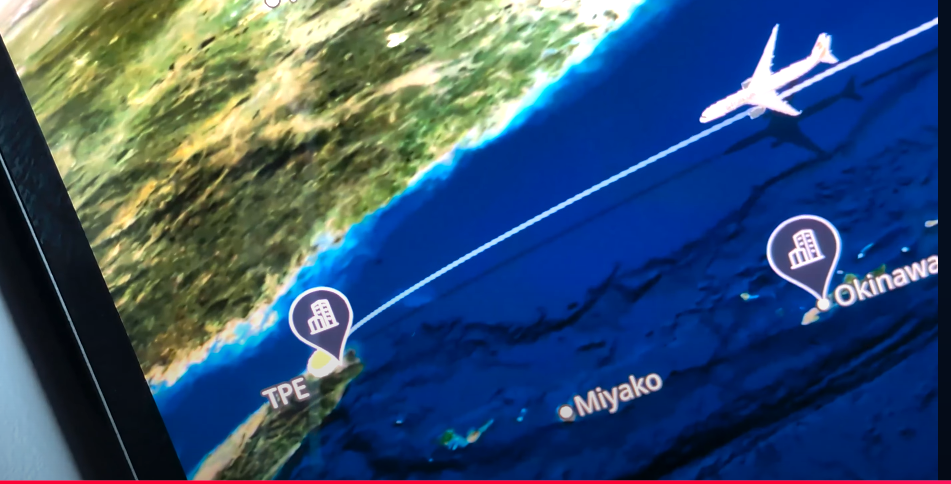
飛んでいる場所がわかれば、前回の問題*10同様、その場所を見るとこの飛行機を見つけられるのではないか。早速やってみる。
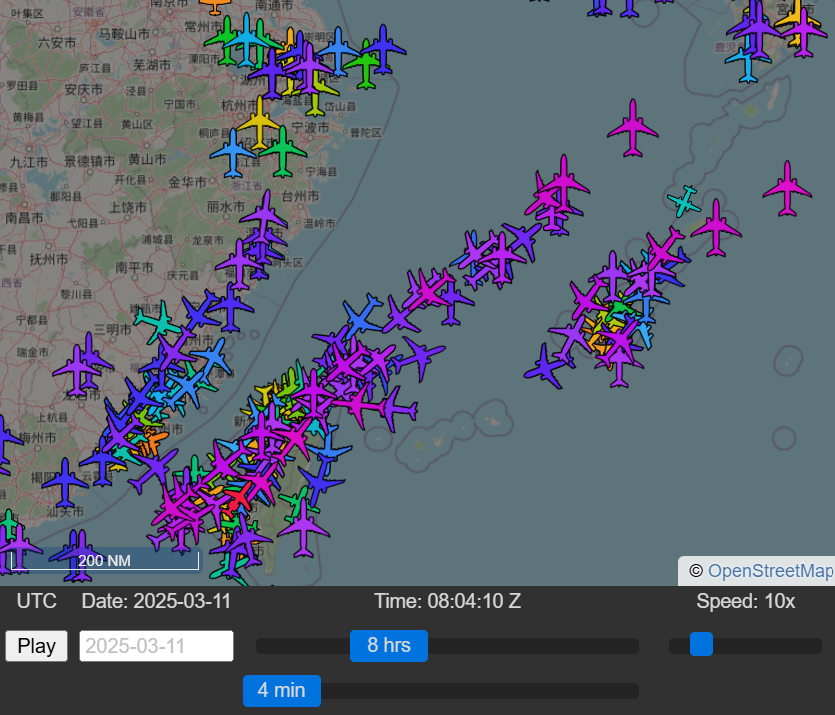
多すぎる。もうちょっとなんとかならないか。
ここで右側にFilter という項目があるのを見つける。Filter by callsign という項目がある。スターラックスの機体に付いているJXで絞り込めばよさそうだ。
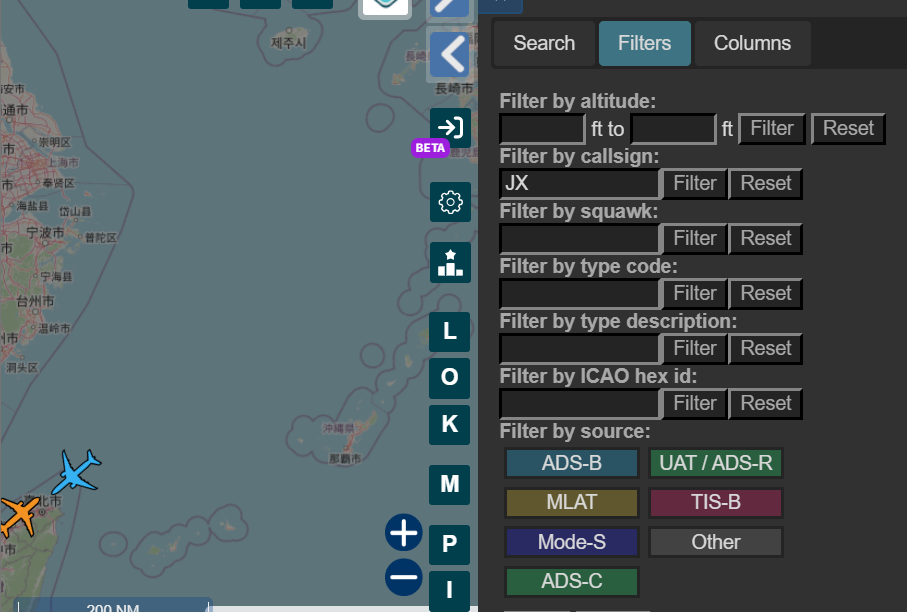
人間が読める感じの情報量に落ちた。
午前中っぽかったので朝8時くらいから記録を回していると、ちょうど9時20くらいに、それらしき位置にSJX803がいる。フィルターを外して他の飛行機も見てみると、超近くに別の飛行機がいる。進行方向左側なので正しそうだ。
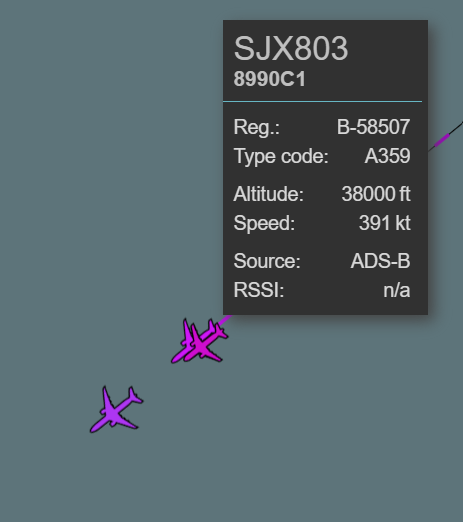
画面に映っているもう片方の飛行機のコールサイン(SKY8026)と機体番号(JA73NY)もわかるので、これをsubmit.
history
bridge [263 pts, 155 solves]
動画 / Video:
https://www.youtube.com/watch?v=fRMi8TXQRuo
(無音です / No audio)
この動画で列車が通過した橋梁は、ある災害で損傷した後に架け替えられたものである。架け替えに際して、他の橋梁の構造物が流用されたことがある文献に示されている。その流用元の橋梁名を答えよ(この橋の名前ではない)。
Flag形式: Diver25{橋梁名}(例: Diver25{日本橋川橋梁})
ヒント:Flagに「山手線」のような路線名は含みません。
ヒント:OCRでは漢字が誤認識されることがあります。もし答えに自信があるのにincorrectとなった場合、別のOCRツールを使ってみてください。
(15 attempts)
とりあえず動画の位置を特定する。Google Lensに掛けたり映った固有名詞をググったり色々した結果、この看板から Naughties.dst という熊本のスロット専門店を見つける。

長薫寺というお寺の外観も一致するので、ここで間違いないだろう。豊肥本線の竜田口駅付近の橋だ。
「竜田口駅 白川 橋梁」で検索すると、この橋が「第二白川橋梁」という名前であることがわかる。
「第二白川橋梁 架け替え」で検索していると、すぐには出てこないが(熊本震災で被災した第一白川橋梁の情報が多数ヒットする)、「熊本県下における近代橋梁の発展史に関する研究」という論文がヒットする。ドキュメント内を「第二」で検索すると、論文29ページに「1953年の白川水害で流失したため、澱川橋梁を転用して架け替えられた」という旨の記述が見つかる。したがって「澱川橋梁」が答えである。
military
object [359 pts, 120 solves]
69.216246, 33.378242 には大きな構造物が存在する。この構造物のプロジェクト番号および、構造物の名称(固有名詞)を現地語で答えよ。
Flag形式: Diver25{プロジェクト番号_名称}(例: Diver25{955А_Борей-А})
ヒント:プロジェクト番号は工場の番号ではない。 / Project number does NOT mean the number of a factory.
(5 attempts)
Lensにかけてみると、記事がヒットする。「AS-31 Losharik」に関連するもののようだ。だがAS-31 は潜水艦そのもののよう)なので、これではなさそう。
範囲を変えてみると、この記事がヒットする。ロシア語で「ПД-72」というようだ。
この名前でググると、プロジェクト番号13560を記載しているサイトがヒットする。
「構造物の名称(固有名詞)」という指定から、「ПД-72」という記号っぽいものを提出していいのかは迷ったが、Diver25{ПД-72_13560}で通った。
hardware
phone [441 pts, 78 solves]

画像から、このデバイスが SH-01J であることが読み取れる。
そもそもEMI試験とは何か?どうやら電磁波の干渉に関する試験のようだ。EMC試験とも呼ばれるらしい。
方針1.deivce.report
検索クエリをいろいろ試す中、docomo SH-01J "EMC" testで device.report というサイトが引っかかる。これ自体はドコモの別のデバイスらしいが、調べると SH-01J についても説明書などが転がっている。その中でも test report というものが興味深いが、残念ながらこのサイトにあるのはすべて広島の会社によるものだった。
方針2. FCC
"SH-01J" test reportでググってみると、(当時の)最新デバイスをまとめているサイトがヒットする。
ここに、次のような記述があった。
FCC(連邦通信委員会)のサイトに、SHARPの未発表端末「SH-01J」が登場。
Test report等から読み取れる情報を、簡単にご紹介します。
ということは、FCCのサイトにtest report が落ちているのではないか?
FCC test report で検索すると、FCC ID Search というそれっぽいものがヒットする。device.report に落ちていた説明書から、SH-01Jの FCC ID が APYHRO00240 であることがわかるので、これで検索を掛ける。
ドキュメントが8件ヒットする。そのうち7件は前述の広島の会社であったが、なんと最後の1件で三重の会社による test report が発見される。日付も7月23日~24日なので正しそうだ。ドキュメントのpdf内を"Serial"で検索して出てくる 004401/11/583099/0 が答え。
company
bid [491 pts, 31 solves]
この問題のwriteupは、「必ず個人の氏名や顔写真をマスクしてください」というルールを遵守して記述されています。
2023年、オマーンにおいて、ある施設に関連するニュースが報じられた。
https://www.youtube.com/watch?v=TFdubskF9Kw
その後、2024年10~11月に、この施設に関連すると推定される、井戸およびパイプラインを建設するための入札が実施された。
このとき、3位の金額で入札した企業のCEOの名前を、Webサイトに掲載されている英語表記で答えよ。
Flag形式: Diver25{Kelly Ortberg}
(7 attempts)
動画のタイトルをブラウザの翻訳機能で和訳すると
アダム州アルバシル地区の獣医病院の管理運営に関する協定に署名。
とのこと。
英語でググって出てこないか、いろいろ試してみると、Oman tender october 2024 Adam State. で、オマーンの入札に関する情報がまとまったサイトがいくつか引っかかる(例1、例2)。ただ、有料会員じゃないと入札者の情報まではわからなさそうだ。
ほかの情報源がないか oman tender でググると、オマーンの公式サイトに入札情報データベースが見つかる。おそらくこれだ。サイトマップから awarded tender の検索ページに飛ぶことができ、これにより入札者の一覧とその入札価格のリストが確認できる。
最初間違って、Oman tender october 2024 Adam State.で引っかかった "Purchase And Supply Of Supplies For The Internal Network Of The Veterinary Hospital In Al-Bishara, Adam State" の入札情報を調べてしまい 1miss。 "Veterinary Hospital" とかあるしこれだ!と思っていたが、弾かれてから入札のタイトルをよく見たら "Internal Network"とか書いているし、当該企業のウェブサイトもどうみてもIT企業で井戸やパイプラインっぽくはない。
その後はあまり覚えていないが、おそらくこのサイトで "Veterinary Hospital pipeline" などと検索して、正しい入札DRILLING WELL BORE SUPPLY& INSTALLATION OF PUMP AND PIPELINE FOR AL-BASHAYER VETERINARY HOSPITAL IN WILAYAT ADAM AT AL-DAKHLIAH GOVERNORATを見つけ出す。これを政府公式サイトのデータベースで検索する。しかし、このタイトルを入れてもなぜかNot Found になってしまう。が、タイトルでGoogle検索していると、政府公式サイトの情報が引っかかる。そこで得られたTender No 1190/2023/MAFWR/DGAWRDK-94- Recall - 1 を使い、政府公式サイトを検索すると無事引っかかる。
名前が GOLDENSANDSTRANSPORTSERVICESLLC となっていたため、適切にスペースを補って出てくる Golden Sands Transports Service LLC のCEOの名前が答え。
ライセンス表示
OpenStreetMap のデータは、オープンデータベースライセンス(ODbL)により提供されます。
https://openstreetmap.org/copyright
*1:余談だが、記事のタイトルに半角閉じかっこが含まれているため、かっこもふくめてURLエンコーディングしなおさないとMarkdown記法のリンクのかっこの中に入れられない
*2:競技終了後、Discordに「回転させて向きを正しくしてからLensに掛けると出てくる」という報告が上がっていた。すごい。
*3:OpenStreetMap の構造物などを条件指定して検索できるAPI
*4:例:「Error: line 15: static error: For the attribute "type" of the element "query" the only allowed values are "node", "way", "relation", "nwr", "nw", "wr", "nr", or "area". と表示されます。.clinics(around.ringhats:50); がまずいようです」
*5:という言い方が合っているかはわからない
*7:例えば公園とコンビニとスーパーが直線状に並んでいると、上記のクエリには引っかかるが問題の条件は満たさない
*8:Discordの情報によれば、どうも正解は放棄された飛行場のようで、OpenStreetMapで調べると出てきたらしい
防衛省サイバーコンテスト2024 writeup
防衛省サイバーコンテスト2024に参加してみました。
防衛省とサイバーコンテストという組み合わせに興味を惹かれ、CTF自体初めてでしたが、勢いで参加してしまいました。
CTFにおいてはWriteupを公開することがあるらしく、参加要領でも「開催時間中の解法の公開は禁止(コンテスト終了後の Writeup 公開は歓迎)」とされていたので、アウトプットと備忘も兼ねて、解けたものについて解法を書いていきます。
あまり多くは解けませんでしたし、解いたものにも力技がいくつかありますが、ご笑覧ください。
Crypto
Information of Certificate(10)
Easy.crt ファイルは自己署名証明書です。証明書の発行者 (Issuer) のコモンネーム (CN) 全体を flag{} で囲んだものがフラグです。
opensslを使うといいらしい。
$ openssl x509 -in Easy.crt -text -noout
Certificate:
Data:
Version: 1 (0x0)
Serial Number: 2024 (0x7e8)
Signature Algorithm: sha256WithRSAEncryption
Issuer: C = XX, ST = Some-State, L = Nowhere, O = Invalid, OU = Invalid, CN = QRK7rNJ3hShV.vlc-cybercontest.invalid, emailAddress = user@QRK7rNJ3hShV.vlc-cybercontest.invalid
...
Missing IV(20)
NoIV.bin ファイルは、128bit AES の CBC モードで暗号化した機密ファイルですが、困ったことに IV (初期化ベクトル) を紛失してしまいました。このファイルからできる限りのデータを復元し、隠されているフラグを抽出してください。暗号鍵は 16 進数表記で
4285a7a182c286b5aa39609176d99c13です。
暗号化鍵がわかっているため、暗号文を素の(ECBモードの) AESで復号できる。ブロックごとに復号したものとその一個前のブロックとをXORしてやれば、IVが必要な最初以外は復元できる。
encs = [] # 後から考えれば、わざわざencsに格納しなくても、最初から読み込んだ順に処理すればよかった with open(f'NoIV.bin','rb') as fr: cnt = 1 read_data=fr.read(16) while(read_data and cnt < 10000): cnt += 1 encs.append(read_data) read_data=fr.read(16) c = AES.new( bytes.fromhex("4285a7a182c286b5aa39609176d99c13"), AES.MODE_ECB, ) decs = [] for i in range(1, len(encs)): enc_block = encs[-i] enc_block_before = encs[- i - 1] x = c.decrypt(enc_block) decs.append(strxor(x, enc_block_before)) with open("result2.odt", "wb") as fw: for d in decs[::-1]: fw.write(d)
出てきたヘッダをバイナリで開くと mimetypeapplication/vnd.oasis.opendocument.textなるものが出てきたので、ググるとOpenDocument Text であることがわかる。
あとは適当なodtファイルからヘッダの欠けている部分を補完してやればwordで開けるようになる。……といいつつこのファイルを開いたら「修復しますか?」と出てきて、補完ステップいらない疑惑が。(後で試したら実際いらなかった)
フラグ獲得。
参考資料
この二つの記事が非常にわかりやすかった。
平文1ブロック目 ^ IV --(AES暗号)--> 暗号1ブロック目
平文2ブロック目 ^ 暗号1ブロック目 --(AES暗号)--> 暗号2ブロック目
Forensics
NTFS Data Hide(10)
NTFSDataHide フォルダに保存されている Sample.pptx を利用して、攻撃者が実行予定のスクリプトを隠しているようです。 仮想ディスクファイル NTFS.vhd を解析して、攻撃者が実行しようとしているスクリプトの内容を明らかにしてください。
ファイルイメージを解析するツールとして autopsy なるものがあるらしい。これでNTFS.vhdを解析してみたら、なんかSample.pptx:script とかいうファイルが出てきた。base64を見つけたのでこれをデコードしてフラグ獲得。
ただ原理はわかっていない。:scriptってなんなんだろう。
NTFS Data Delete(10)
NTFSFileDelete フォルダにフラグを記載した txt ファイルを保存したのですが、どうやら何者かによって消されてしまったようです。
問題「NTFS Data Hide」に引き続き、仮想ディスクファイル NTFS.vhd を解析して、削除された flag.txt に書かれていた内容を見つけ出してください。
「削除されたファイル」にflag.txtがあったので、ここからフラグを回収。
flag{resident_in_mft}
My Secret(30)
問題「HiddEN Variable」に引き続き、メモリダンプファイル memdump.raw を解析して、秘密(Secret)を明らかにしてください。
問題の順序はこれが最後だけど、メモリダンプを解析するツール Volatility3 をポチポチ触ってたらクリティカルなコマンドを打ってしまったのでこっちがさきに解けてしまった。
最初Volatile2 を使うも、profileの特定のためのimageinfoがうまくいかなかったし、stringsの出力を見てもWindowsであること以上はわからなかったので断念。Volatile 3のほうがよいという情報を見たこともありVolatile3に移行。
適当にコマンドを試す中で ./vol.py -f ../memdump.raw windows.cmdline とか打ったら
5516 7z.exe 7z x -pY0uCanF1ndTh1sPa$$w0rd C:\Users\vauser\Documents\Secrets.7z -od:\
とかいう死ぬほど怪しいログを見つけてしまった。どうやらこれは起動中のコマンドの引数を表示してくれるらしいので、次の目標がSecrets.7zを見つけることになる。
file系ということでfilescanとfiledumpを試す。まずはfilescanから。そのままだと大量に出てくるので grep で絞り込みをかける。
$ ./vol.py -f ../memdump.raw windows.filescan | grep Secret 0xe206bba6b1d0.0\Users\vauser\Documents\Secrets.7z 216 0xe206bbc4a2f0 \Users\vauser\Documents\Secrets.7z 216
filedumpの--virt_addrに与えるのはこれか。--physaddrと迷ったけどこっちで決め打ち。
$ ./vol.py -f ../memdump.raw windows.dumpfiles --virtaddr 0xe206bbc4a2f0
lsすると
file.0xe206bbc4a2f0.0xe206bbabada0.SharedCacheMap.Secrets.7z.dat file.0xe206bbc4a2f0.0xe206bbabada0.SharedCacheMap.Secrets.7z.vacb
なる物々しいファイル名が出てくるが、datのほうを普通にSecrets.7zにリネームしてOK。あとは最初に出てきた7z.exeの引数にあったパスワードを使って解凍するとSecrets.rtfが出てきてフラグ回収。
このときはcatで中を見たから気が付かなかったが、後でwordで開いてみたらflagは丁寧に白文字になって隠されていた。

参考資料
HiddEN Variable(20)
NTFSFileDelete フォルダにフラグを記載した txt ファイルを保存したのですが、どうやら何者かによって消されてしまったようです。 このメモリダンプが取得された環境にはフラグが隠されています。 memdump.raw を解析して、フラグを見つけ出してください。
メモリダンプファイルのダウンロードはこちら: メモリダンプは展開すると 4.5GB 程度になるので注意してください。
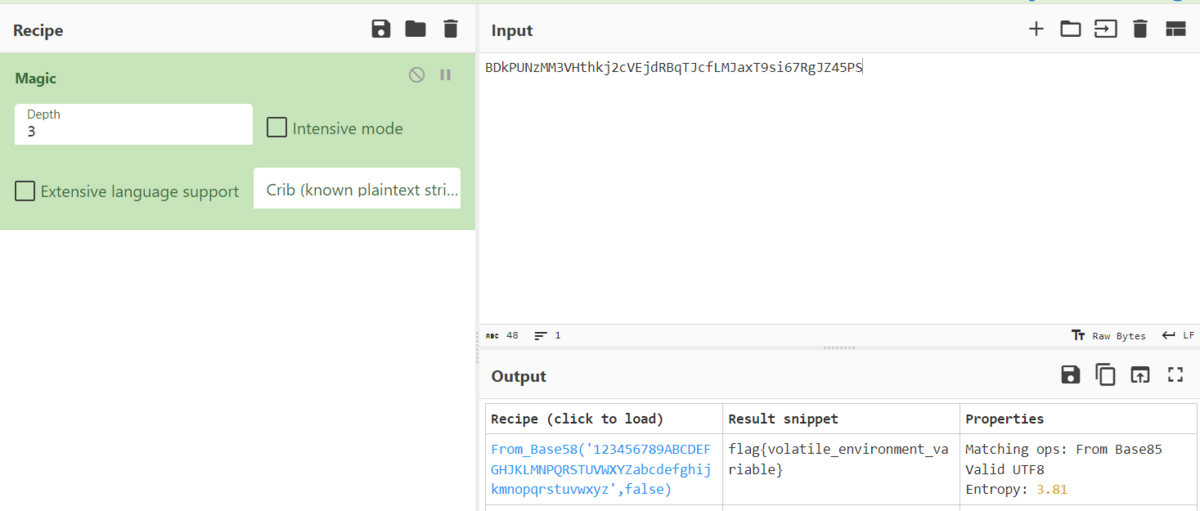
「取得された 環境 には」だし、ENvironment Variable か。環境変数を取得するコマンドがヘルプになくてわからなかった(ので飛ばしていた)が、ググるとwindows.envarsなるコマンドがあることが分かった。
すごい量のログが出てくるが、
FLAG BDkPUNzMM3VHthkj2cVEjdRBqTJcfLMJaxT9si67RgJZ45PS
なるものを発見。
flag{BDkPUNzMM3VHthkj2cVEjdRBqTJcfLMJaxT9si67RgJZ45PS} は通らなかったのでもうひとひねり必要だった。base64でもなかったので、ほかにこの文字列が現れる場所があるのか、そもそもこのFLAGSは本当にフラグなのか、と思っていろいろコマンドを打ってはみたが、結局CyberChefでMagicしてみたらflagが出てきてしまった。
NTFS File Rename(20)
NTFSFileRename フォルダに保存されている Renamed.docx は、以前は別のファイル名で保存されていました。
問題「NTFS File Delete」に引き続き、仮想ディスクファイル NTFS.vhdを解析して、 Renamed.docx の元のファイル名を明らかにしてください。
Autopsyを探し回っても出てこなかったので、resident_in_mftって言ってたし出てこないかなーくらいのつもりでNTFS.vhdをstringsにかける。有意な情報は出てこない。バイナリエディタで見る。有意っぽい文字列が、間にゼロをはさみつつ登場していることがわかる。だからstringsに出てこなかったのか。

ただそれ以外のところで0のバイトが大量に出てきすぎて、スクロールしてもスクロールしても終わらず、諦める。
いっそpythonでゼロになってるバイトを取り除くとスクロールしやすくならないかな?って思って実装。これをバイナリエディタで見るとフラグが出てきた。……たぶん想定解じゃないよなあ。
Miscellaneous
Une Maison (10)
画像 maison.jpg の中にフラグが隠されています。探してみてください。

この記事の手法をひととおり試してみたものの当たらなかった。しかし「意外と一番重要かもしれない」というこの記事の導きに従い、画像検索で元ファイルを探して、gimpで重ねて見比べると画像の一部がバーコードになっていることがわかった。これを読み込むとフラグ獲得。
String Obfuscation (10)
難読化された Python コード string_obfuscation.py ファイルからフラグを抽出してください。
import sys if len(sys.argv) < 2: exit() KEY = "gobbledygook".replace("b", "").replace("e", "").replace("oo", "").replace("gk", "").replace("y", "en") FLAG = chr(51)+chr(70)+chr(120)+chr(89)+chr(70)+chr(109)+chr(52)+chr(117)+chr(84)+chr(89)+chr(68)+chr(70)+chr(70)+chr(122)+chr(109)+chr(98)+chr(51) if sys.argv[1] == KEY: print("flag{%s}" % FLAG)
if文消したら普通に動いた。
Where Is the Legit Flag?(20)
fakeflag.py を実行しても偽のフラグが出力されてしまいます。難読化されたコードを解読し、本物のフラグを見つけ出してください。
exec(chr(105)+chr(109)+chr(112)+chr(111)+chr(114)+chr(116)+chr(32)+chr(122)+chr(108)+chr(105)+chr(98)+chr(44)+chr(32)+chr(98)+chr(97)+chr(115)+chr(101)+chr(54)+chr(52)) TANAKA = "eJyNVG1320QT/Z5z8h+GhNYvcR35JZZdaCGhT6D0gQTiFKjjlpU0ljZe7272xYpoy2/vrJRA+MA56IOPrJ29e+feO7sP84JJ2CohsEqYELBlktsCWM64tA6E3+gKEjSm6u/uXBzPz+AZtBY/vRx91Unffv908vOrw9PXz7/E23h/nf2mtp9/Gz05fn9zbv8sB18f/P7DWa9o/5/1f/Hf6KMlhzfJ9YvZ/x4NKzk185PNF6vud3uf/Xjx0eV/PLsUvz4ev/tw1bq6au3u7MNxorYIK5Yi4K0WRAhWyoAuKstTJiDDlFuuZB9C9WvOwEq2RpBsg2CUlxk4Is5XPIXEMGubwlNqVpVc5mB9nqN1BAG2LjeYM5OFpRVumCAUTPF+31yVtAhb+oB0OLcsN4ikjUTmCih8jqCVoSODUpdvLl+9JK0W8fhJdBD1dnfg7pnG3UGPS9ceT7vdQYdW9uFstQLtjVYWQTBiwiwYb6hJ65jDDUpHoPcIYfP03ahTo4yG/Sg8zb/WaNwKkPel8QQeQ3R7etqLh/CB3qKoF8/gbfO2mBwtF9GypvDCm9D4WipHbYsKLCP1S4MuLTADmzISw6gyiHGP3h52euMY+ArmxpNLguhHNY/B8JBaG0TwCAaDnjJZOy1MezjpPCQ3ig6O7pQ4HHYJa9adLQMXOBfeglMIFp0jH0pOCm8ZBZJSialrHIGLQJECnFmwBQqSvqk0zLkKtFGZT5GEo9Iz7yzPSF3MLUhynYw0NpximLzxXISmWchCU39soWRiDZqRHE04eF64lRfAsi0n2JrCCdaomlXBowBGKU0qMtFQHNYYpmYfzgPzBAu25SHAiv65Jk1esoT6K9TmDhCON4psoLhT7FO1aXKfKhnOqR3ykjwq6Zs3pslFG8K+hqXVzKzJLWVSmuJ6gqxWQY7cMF0fEqRvtWjLpSTIJr3XWFKo00Jp6oXoZaiRVqklmh8RNAy7+uHnWhGhf33ai7/9DQ5xWfeRlJiA4wiKkl544yjYoZu7S2XBl38h/Ldd4SbglAZoJu3hoRRHDs9hHA+nT/9Bhp7EIFs//OhoRoej8WQSQxemo3h69HBV02mu7Q5H46M4no46tUPzgqTOC7jxiBIytiF6YAXXGk1Ve8YMt3WQls2OkyqEKQyzUXRBhYwqT83QQKGjJVtQbVN6pike3CFUoVIijV7SZMx6wk/CjUzXcfCxIbe3Eip/P91e46z0MtGz6fjjHmHt7nwCLpe/Qg==" TAKAHASHI = [0x7a,0x7a,0x7a,0x12,0x18,0x12,0x1d,0x12,0x07,0x7b,0x36,0x37,0x3c,0x30,0x36,0x37,0x67,0x65,0x31,0x7d,0x67,0x65,0x36,0x20,0x32,0x31,0x7b,0x20,0x20,0x36,0x21,0x23,0x3e,0x3c,0x30,0x36,0x37,0x7d,0x31,0x3a,0x3f,0x29,0x7b,0x30,0x36,0x2b,0x36] exec(bytes([WATANABE ^ 0b01010011 for WATANABE in reversed(TAKAHASHI)]))
実行すると出てくるのはflog{8vje9wunbp984} だが、これは当然通らない。
とりあえずexecの中身を確認。
1個目は import zlib, base64 。2個目はexec(zlib.decompress(base64.b64decode(TANAKA)))'。もう一回execの中身を確認。すると、大量のコメントの中に
SATO = ... SUZUKI = ... (''.join([SATO[i] for i in SUZUKI])) print("flog{8vje9wunbp984}")
というコードが埋もれているのを発見。3行目をprintすればflagが出てくる。
Utter Darkness(20)
真っ黒。実は真っ黒に見えて画素値1/255で書いてたりしない?と思ってpythonで読み込んで画素値を調べてみるも、全部ゼロ。 ただバイナリを見ると全部同じ値というわけではない。???と思ってbmpのヘッダを解読すると、どうやら画素を表現する値(0/1)は、直接色を指定しているわけではなく、ヘッダにあるパレットの番号を表しており、これによって色を指定しているらしい。そのパレットの色が0も1も真っ黒(0x000000)になっていたことが原因だった。片方を白(0xFFFFFF)に書き換えたらフラグが出てきた。
参考資料
Serial Port Signal(30)
Tx.csv は、とあるシリアル通信の内容を傍受し、電気信号の Hi, Low をそれぞれ数字の 1 と 0 に変換したものです。通信内容を解析してフラグを抽出してください。
中身はmicroseconds(20μs刻み)とlogic(0/1)の対応表。どっかで見たことあるなと思いつつ「シリアル通信 Tx」などと検索するとUARTが出てくる。学部の実験でやったところだ!!!!!
0/1の切り替わりが最短でも100μsほど空いていたことから、baud rate は9600だろうとあたりをつけてuartのシミュレータをpythonで書く。いろいろネットで検索したけど実装の詳細がよくわからず、授業で配布された資料を引っ張ってきて書いた。やっぱりわかりやすかった。送信が7bitであることとparity bit があることが最初わかっておらず、結果がちょっとずれて原因の特定に時間を食った。
def get_logic(df, t): ret_df = df[(df["microseconds"] <= t)]["logic"] if(len(ret_df) == 0): return 1 return int(ret_df.iloc[-1]) baudrate = 9600 dt = 1000 * 1000 / baudrate t = 5460 # 最初のlow bit の開始時刻 t += dt / 4 while(t < 40940): while(get_logic(df, t) == 1): t += dt s = "" for i in range(7): t += dt s = str(get_logic(df, t)) + s t += dt # parity t += dt if (get_logic(df, t) != 1): print(f"ERROR on t = {t}") print(chr(int(s, 2)))
Hello UART: synt{IjUZC5TD} Hell
やっぱUARTか。rot13かな?とあたりをつけたらやっぱりrot13だった。
flag{VwHMP5GQ}
参考資料
パリティビットの存在と、データが8bitでない場合があることは知らなかった。
Network
FileExtract(10)
添付の FileExtract.pcapng ファイルからフラグを見つけ出し、解答してください。
Network解けたのはこれだけだった。
pcapngを解析するためにはWiresharkがよいらしい。眺めると、FTPでs3cr3t.zipを送っているログを発見。ファイルを書き出す方法を発見したのでs3cr3t.zipを落として展開。
……パスワードに阻まれる。ログのFTPをもう一回探すと
FTP Request: Pass br2fWWJjjab3
なるものを見つける。これを打ち込むと解凍に成功。パスを取得。
その時は何も考えなかったけど、FTPのログインパスワードとzipのパス同じってことだろうか。実質PPAP?
参考資料
Programming
Logistic Map(10)
下記のロジスティック写像について、x_0 = 0.3 を与えた時の x_9999 の値を求め、小数第7位までの値を答えてください(例:flag{0.1234567})。なお、値の保持と計算には倍精度浮動小数点数を使用してください。
x_{n+1} = 3.99 x_n (1 - x_n)
double x = 0.3; for(int i = 0; i < 9999; i++){ x = (double) 3.99 * x * ((double) 1 - x); } cout << std::setprecision(7) << x;
Randomness Extraction(20)
ファイル random.dat は一様でない乱数生成器の出力ですが、一部にフラグが埋め込まれています。フォン・ノイマンランダムネスエクストラクターを適用してフラグを抽出してください。
フォン・ノイマンランダムネスエクストラクター、初耳だった。カタカナで検索しても出てこないが、英語で検索をかけると出てくる。
2bitずつ読み込んで
| src[2*i] | src[2*i+1] | 操作 |
|---|---|---|
| 0 | 0 | skip |
| 0 | 1 | dst[j]=0; j++; |
| 1 | 0 | dst[j]=1; j++; |
| 1 | 1 | skip |
みたいな処理をするらしい。
最初、これを6~7回くらい繰り返し適用したらflagになるのかな~とか思ってたけど何も出てこず、一旦飛ばしていた。最後30分くらいで見直したら1回目の適用結果(のバイナリ)にflagが普通に紛れ込んでいた。
参考資料
XML Confectioner(20)
添付の sweets.xml には、多数の sweets:batch 要素が含まれています。これらの中から、下記の条件すべてを満たすものを探してください。
少なくとも二つの子要素 sweets:icecream が含まれる 子要素 sweets:icecream には icecream:amount 属性の値が 105g を下回るものがない 子要素 sweets:candy の candy:weight 属性の値の合計が 28.0g 以上である 子要素 sweets:candy の candy:shape 属性が 5 種類以上含まれる cookie:kind 属性が icing でありかつ cookie:radius 属性が 3.0cm 以上の子要素 sweets:cookie を少なくとも一つ含む フラグは、条件を満たす sweets:batch 要素内において、最も cookie:radius 属性が大きな sweets:cookie 要素の内容に書かれています。
xml.etree.ElementTree でひたすら処理する。
tree = et.parse("sweets.xml") root = tree.getroot() ans = [] for child in root: icecream = [] candy = [] cookie = [] for c2 in child: if ("icecream" in c2.tag) : icecream.append(c2) if ("candy" in c2.tag) : candy.append(c2) if ("cookie" in c2.tag) : cookie.append(c2) if len(icecream) < 2: continue prefix_icecream = "{http://xml.vlc-cybercontest.com/icecream}" prefix_candy = "{http://xml.vlc-cybercontest.com/candy}" prefix_cookie = "{http://xml.vlc-cybercontest.com/cookie}" skipFlg = False for i in icecream: if float(i.attrib[prefix_icecream + "amount"][:-1]) < 105: skipFlg = True break if skipFlg: continue s = 0 shapes = set() for c in candy: s += float(c.attrib[prefix_candy + "weight"][:-1]) shapes.add(c.attrib[prefix_candy + "shape"]) if s < 28.0: continue if(len(shapes) < 4): continue for c in cookie: if (c.attrib[prefix_cookie + "kind"] == "icing" and c.attrib[prefix_cookie + "radius"][:-2] >= "3.0"): ans.append(child) break for a in ans: max_rad = -1 max_rad_c = None for c in a: if "cookie" in c.tag: if max_rad < float(c.attrib[prefix_cookie+"radius"][:-2]): max_rad = float(c.attrib[prefix_cookie+"radius"][:-2]) max_rad_c = c print(max_rad_c.tag) print(max_rad_c.attrib)
Trivia(各10点)
Q. Advanced Encryption Standard (AES) は、公募によって策定された標準暗号です。 現在採用されているアルゴリズムの候補名は何だったでしょうか?
A. Rijndael
Q. 最も番号が若い CVE レコードのソフトウェアパッケージにおいて、脆弱性が指摘された行を含むソースファイル名は何でしょう?
CVEレコードの一覧がだいぶ見つけづらかったが、 https://www.cve.org/Downloads を発見すれば最も若い番号がCVE-1999-0001であることがわかる。画面上部の検索窓に打ち込めば答えが見つかる。
A. ip_input.c
Q. 多要素認証に使われる本人確認のための3種類の情報の名前は何でしょう?それぞれ漢字2文字で、50音の辞書順で並べて「・」で区切ってお答えください。
A. 所持・生体・知識
Web
Browsers Have Local Storage(10)
http://10.10.10.30 にアクセスしてフラグを見つけ出し、解答してください。
右クリックメニューからInspectを選び、Storage > Local Storage を見るとフラグが見つかる。

結果・感想


Webやネットワークがほとんど解けなかったのが少し悔しいです。
一日丸々費やしてかなり疲れましたが、Google検索と地道な調査と閃きで進んでいくのが楽しかったです。
解けなかった問題や、解けても力技になった問題は、他の方のwriteupを見るなどして学習してみたいと思いました。
ソフトウェアシンセサイザーを実装するときにピッチを揺らす方法
結論
周波数 が時刻変化するとき、sin関数等に与えるべき位相は「
×周波数」の積算値(積分)であって、
ではない。
実装例(C#)
- 時刻
における周波数
は、
- 時刻
は、
- よって、
const int SAMPLE_PER_SEC = 48000; float length = 2; float sample_size = SAMPLE_PER_SEC * length; float[] waveform = new float[sample_size] ; float phase = 0; float base_freq = 440; // A4(hiA) 「栄光の架橋」の最高音らしい float base_amp = 1; float LFO_freq = 1; float LFO_amp = 2 / 12; // 上下に全音一個分ずつ揺らす for (int sample = 0; sample < sample_size; sample++) { float t = sample / SAMPLE_PER_SEC; float LFO_value = LFO_amp * MathF.Sin(2 * MathF.PI * LFO_freq * t); float frequency = base_freq * MathF.Pow(2, LFO_value); float dt = 1.0F / SAMPLE_PER_SEC; phase += 2 * MathF.PI * frequency * dt; // 周波数を 2 * PI に収める処理 if (phase > 2 * MathF.PI){ phase -= 2 * MathF.PI; } float val = base_amp * MathF.Sin(phase) ; waveform[sample] = val; }
備考
失敗例
- 時刻
(定義)
- 波の方程式、
(
が一定値なら正しい)
- よって、
(間違い)
const int SAMPLE_PER_SEC = 48000; float length = 2; float sample_size = SAMPLE_PER_SEC * length; float[] waveform = new float[sample_size] ; float phase = 0; float base_freq = 440; float base_amp = 1; float LFO_freq = 1; float LFO_amp = 2 / 12; for (int sample = 0; sample < sample_size; sample++) { float t = sample / SAMPLE_PER_SEC; float LFO_value = LFO_amp * MathF.Sin(2 * MathF.PI * LFO_freq * t); float frequency = base_freq * MathF.Pow(2, LFO_value); phase = 2 * MathF.PI * frequency * t; // y = A sin(2 * pi * f * t) <-- 間違い float val = base_amp * MathF.Sin(phase) ; waveform[sample] = val; }
これをやると、ピッチが宇宙の彼方へと飛んでいきます。それもそのはず、位相が のとき、周波数はこれを微分した値
で、tが大きくなるとどんどん大きくなっていきます。
最初LFOを で実装してしまい、これが下手に解析的に積分できてしまうせいで、正しく
(解析的に積分できないらしい)で実装したりADSRエンベロープを実装したりしようとしたときに、数値積分という発想に至らず、しばらく泥沼にはまってしまったので、書き残してみます。
参考資料
CPU実験の記録(byコンパイラ係)
はじめに
この記事は、僕のコンパイラ係としての活動をまとめたものです。
CPU実験の紹介
東京大学理学部情報科学科の3年後期(Aセメスター)には、「プロセッサ・コンパイラ実験」(通称「CPU実験」)という名物授業があります。この実験はざっくりというと「CPUを自作しよう!」というものです。学科の30人が各3~4人の班に分かれて、それぞれが「コア係」「FPU係」「シミュレータ係」「コンパイラ係」を担当することになります。
それぞれの係の詳細な説明は他の記事に譲りますが、大まかにはコア係がいわゆる中央演算装置(命令を読み込んで、演算して、結果をレジスタやメモリに書き戻す回路)を作ります。FPU係はこれに組み込むFPU(浮動小数点演算装置)を作ります。シミュレータ係はこのコアにおける命令列(プログラム)の実行結果をC++等(に限らず好きな言語)でシミュレートするソフトウェアを書きます。*1
そしてコンパイラ係の仕事は、大まかには次のようなものです。
- MinCamlという言語*2で書かれたソースコードを読み込んで、自分たちのISA(CPUが読み込む命令列のフォーマット)に則ったアセンブリを生成する
- 動作を変えない範囲でできる限り効率の良いコードを作成するよう最適化する
コンパイラ実験の課題をやる*3
コンパイラを書くのに使う言語はなんでもよいですが、 OCamlで書かれたMinCamlコンパイラが公開されているので、これをベースに、自班ISAへの変更、種々の最適化、等の改造を加えていく人が多いです。僕もその方針をとりました。また、RustとかPythonとかを使って一から全部自分で書く(フルスクラッチ)していた人もいました。
なお、対象とするプログラムはレイトレーシング*4を実行するプログラム(minrt)です。完全に正しく動く(いわゆる完動)と次のような画像が出ます。

アセンブラについて
なお、これら4つの係のほかにも、どの係にも属さない(よって誰がやってもいい)仕事として、アセンブリを吐いた後に、それをCPUが読める形式である機械語に直すという仕事(アセンブラの作成)があります。うちの班では、これは神たるシミュレータ係にお任せすることになりました。
この判断は次の理由から大成功だったと思っています。
第一に、コンパイラ係としては、アセンブリさえ吐けば、その後の機械語への変換は気にしなくてよくなりました。もしコンパイラ係がアセンブラも書いていたら、「シミュレータ上でうまく動かない」理由がコンパイラのせいなのかアセンブラのせいなのかがわからず、デバッグ作業が大変になっていたでしょう。(コンパイラ係はアセンブラのバグを踏まなかったので、実際にバグったらどうなったかについては何とも言えないですが……)
第二に、機械語に「もとのアセンブリの何行目か」という情報を埋め込むことで、シミュレータの実行時「現在実行している場所やブレークポイントは、もとのアセンブリの何行目か」という情報が得られるようになりました。この作業も死ぬほど面倒だったようなので、シミュレータ係以外がアセンブラを書いていたらなおさら面倒だったでしょう。
やったこと(時系列順)
日記のようなものです。
シミュレータ上完動まで(~11月上旬)
第1週の班の顔合わせの時、コア係がいきなりISAを持ってきました。びっくりしたのですが、今思えばこれが相当のアドバンテージで、第1週からもう自班ISA向けの改造を始めることができました。また、前述のとおりアセンブラをシミュレータ係にお願いしていました。そのおかげでコンパイラに集中できたのも大きいです。
種々の最適化(コンパイラ実験の課題)と並行して改造を進め、第1週終了時にはデバッグ段階に至り、第2週終了時にはレイトレのコードをエラー落ちせずにコンパイルできるようになりました(結果はもちろんまだ正しくない)。そこからアセンブラが文法エラーを出さないようなコードを生成できるようになるまでが長く*5、結局第5週までかかりました。
アセンブラに通ってからは、運のいいことにデバッグが素直に終わり(クロージャ回りが相当の闇でしたが…)11/7にシミュレータ上で完動させることができました。
中間コードの出力と、中間コードや出力コードと元のプログラムの対応関係の明示
第1週に、コンパイラ実験第1回課題として実装しました。MinCamlコンパイラのプログラムを初めて読んだ段階で全体をいじらなきゃいけないため、死ぬほど大変な作業でした。が、以降のデバッグにものすごく役に立ちました。
ついでに、コンパイルオプション-kindとして指定することで、(ほぼ)任意の最適化の直後の中間コードを出力することができるようにもしています。これは第3週くらいに実装しました。
コンパイルオプション
ここでついでにコンパイルオプションについて述べます。もともとmin-camlにも、インライン展開する関数のサイズ-inline、最適化適用の繰り返しの回数-iterを指定するオプションがあったのですが、コンパイラを使いやすくするため、上述の中間コード出力を含め、他にもいろいろコンパイルオプションを実装しました。
たとえば、-id XX と指定することで、出力ファイルの末尾にXXという文字列を追加できます。適用する最適化の種類や条件を変えて出力結果を比較するときに便利でした。また、-on XX -off YYとすることで、最適化XXを適用し、最適化YYを適用しないことができるようになります。「特定の最適化の組み合わせによりバグが生まれることもあるので、原因を切り分けるため最適化をオンオフすることができるとよい」と先輩のブログにあったので、実装してみたところ、非常に助けられました。
これらのオプションを駆使して、
./min-caml minrt -kind Logic -iter 3 -off Tuple -id 3 ./min-caml minrt -kind Logic -iter 2 -off Tuple -id 2
などと指定し、吐き出されたminrt_Logic_3, minrt_Logic_2を眺めて、3回目の最適化でバグった最適化Logicを修正していました。
共通部分式削除
初出はコンパイラ実験第2回課題でした。
特筆すべきこととしては、副作用の扱いです。副作用のある共通部分式を削除してしまうとプログラムの意味が変わってしまいます。たとえば、極端な話
let _ = print_int 1 in let _ = print_int 1 in ...
のprint_int 1は共通部分式ですが、当然これを削除するとまずいです。しかし、副作用の有無は判定不能なので、ある程度保守的な判断をせざるを得ません。
同様の判定はElim.f(MinCaml組み込みの不要定義削除)でも必要となりますが、これを流用すると「関数呼び出しや配列への書き込みはすべて削除しない」ことになってしまいます。例えば、
let rec fib x = if x <= 2 then 1 else (fib (x-1)) + (fib (x-2)) in let a = fib 10 in let b = fib 10 in ... let _ = arr.(0) <- a in let _ = arr.(0) <- a in ...
のような場合は共通部分式削除が実際にはできるのに、「できない」と判断されてしまうことになります。
そこでより厳しい判定条件として、「関数間解析とエイリアス解析により副作用のありなしをより厳格に判断する」という方針の実装をしました。
関数は、その本体とその関数が呼び出す関数の中で両方副作用がないならば、副作用がない。
配列への書き込みは、値の同一性が保証されている限りは副作用がない。
ということです。
この工夫によっては、実装時点ではコンパイル結果に影響を与えませんでした。しかしその後第12週に、shadow_check_one_or_matrixの中のshadow_check_one_or_groupの呼び出しが一部無駄であることに気づきました。shadow_check_one_or_groupは実質的には副作用がないのに、下手に配列の書き込みをやっているせいで「副作用がある」と判定されてしまっていました。単純化すれば
let rec f x = arr.(0) <- x; fib x in ...
みたいな構造です*6。
これをうまく「共通部分式削除できる」と判定することで共通部分式削除ができるようになり、1億命令ほど削減できました。
ただし、結局エイリアス解析は完全に嘘実装で実質的には機能していませんでした。これによりバグを踏んでしまったので、配列書き込みそのものの共通部分式削除は無効化してしまいました。
あとは、あんまり離れた共通部分式を削除してしまうと、レジスタ負荷が高まって逆によくないという話があり、その制御も実装しています。
ラムダリフティング
第3週に、コンパイラ実験第3回課題として実装しました。が、グローバル変数のメモリ番地固定化を導入すると、関数から自由変数が全部消えるため、結局実装の必要はそんなになかったです。
タプル平坦化
第4週~第5週に、コンパイラ実験第4回課題として実装しました。これが相当の曲者でした。
まず、実装方針が非常に面倒です。本当は必要なタプルだけを展開するのが望ましいのですが、よくよく考えるとこのタプルを展開するとこれも展開しなきゃいけなくなり、これも展開して……となってしまい、結局「すべてのタプルを展開する」のが一番楽になってしまいます。
しかし、すべてのタプルを展開すると、今度は異常にレジスタ負荷が大きくなってしまいます。さらに関数引数のタプルを展開した場合、引数がレジスタの個数(32個)に収まらなくなったりしてしまいます。そこで、「要素数n以下のタプルのみを展開する」という方針に移行しました。これもまた面倒で、たとえばn=2のとき(((1, 2, 3), (4, 5, 6)), 7)をどこまで展開するか?とか、いろいろ大量のコーナーケースが生じるので、これらを矛盾することなく処理する必要がありました。
また、タプルの配列の扱いについて、コンパイラ実験では
let arr = create_array 5 (1, 2) in ...
を
for(int i=0; i++; i<5){ arr[2*i] = 1; arr[2*i+1] = 2; }
に書き換える方針が示されていましたが、これでは配列アクセスのたびにindexに2を掛ける必要があって非効率なことに気づきました。なので、
let arr1 = create_array 5 1 in let arr2 = create_array 5 2 in ...
に書き換えるという効率化も行いました。
ここまでやっても、実行命令数自体はタプル平坦化を導入するほうが多くなってしまいました。その原因は、実装時点ではレジスタ負荷の問題だろうか、とか考えていました。これはある意味正解で、実行命令数は後述のグローバルレジスタ割り当てを実装してやっと減りました。関数呼び出し時生きている変数をstoreしなければいけないのが相当悪影響を与えていたようです。
完動からA1ターム終了まで(11月)
このあたりの無限最適化編が一番楽しかったです。まず共通部分式削除とインライン展開のパラメータをいじって50億命令くらいになりました。論理に関する最適化や、(float_of_int x) *. (float_of_int 2^n) をshift_left x nに置き換えたりするようなこまごました最適化を実装したりして40億命令にまで減らしました。さらに即値の利用(addiとかlw 4, 4(x4)とか)により、40億命令→30億命令くらいにまで減りました。この瞬間は本当に気持ちよかったです。
その後なんやかんやで25億命令まで減り、グローバル変数の導入で21億命令まで減りました。
論理に関する最適化
let b = if x = y then 1 else 0 in let x = if b = 0 then e3 else e4 in ...
は
let x = if x = y then e4 else e3 in ...
に置き換えたほうがお得です。より一般に、「then 1 else 0」ではなく「then e1 else e2」とかでも
let x = if x = y then if e1 = 0 then e4 else e3 else if e2 = 0 then e4 else e3
とかにしたほうがお得です。then 1 else 0の場合より単純化できるという話も、MinCamlデフォルトの定数畳み込みがよしなにやってくれます。
なお、あんまりやりすぎるとコードサイズ爆発を招く最適化ですが、minrtの場合は動くのでヨシ!
即値の利用
特筆すべきことはそんなにないのですが、
addi tmp, x0, 8 # tmp = 8; add b, a, tmp # b = a + tmp;
を
addi tmp, x0, 8 addi b, a, 8
に置き換えた結果不要になるtmp, どこに行ったんだろうなーとか思っていたのですが、MinCamlデフォルトのSimm18で消えていました。すごいなと思いました。
グローバル変数の導入
これも先述の先輩のブログが詳しいですが、minrtではプログラムの最初(というかglobals.ml)でグローバル配列を確保しており、レイトレ本体の中ではこれに対してload/storeを行っています。これを「変数に格納されたアドレスへのload/store」とみなすと関数内に自由変数が大量発生し大変なことになります。しかし、変数を確保するタイミングがプログラムの先頭であることを利用すればこれらのグローバル配列のメモリ上の位置は確定するので、グローバル変数をすべて定数に置き換えてやれば、「定数アドレスへのload/store」とみなすことができます。すると、自由変数はなくなるわ、アドレス計算等の定数畳み込みは促進されるわで幸せになれます。
年末まで(11月下旬~12月)
グラフ彩色によるレジスタ割り当て
このあたりでできる最適化が少なくなってきて、グラフ彩色によるレジスタ割り当てを実装しようと試みます。しかし、これが相当の地獄でした。
そもそもMinCamlにデフォルトで入っている貪欲なレジスタ割り当ては、単純な割にそんなに効率が悪いものではないです。一方グラフ彩色レジスタ割り当ての実装として参照するのはタイガーブックのアルゴリズムですが、これはかなり複雑です。まず生存解析の実装に2週間かかってしまいました*7。そのうえで彩色問題を解いたりSpillやCoalescingを考えつつうまいレジスタ割り当てを考えたり、callee save register*8を導入したり…などと考えると、効率の良いレジスタ割り当てにはかなりの時間的コストがかかります。
結局、「最適化だけを考えるならほかの部分に注力したほうがよい」という判断を下してしまい、グラフ彩色をあきらめてしまいました。
命令スケジューリング
グラフ彩色を凍結した後、コンパイラ実験第8週の課題として実装しました。lwの結果が返ってくるまでにaddiなどの別の命令を実行しておこう!というやつです。
単純なコアにおける命令スケジューリングについてはコンパイラ実験のスライドが割と詳しいのですが、うちの班ではコア係がスーパースカラプロセッサを作ってくれたので、資源制約の部分が少し特殊で、スーパースカラプロセッサをシミュレートするようなスケジューラを作成しました。すなわち、「現在発行できる命令」や「今実行しているこの命令は結果が返ってきているか」等を管理しておき、できる限り2命令を同時発行できるようにスケジューリングしています。
このときに同時発行できる命令の条件についてコア係さんに聞いてみたのですが、かなり複雑でびっくりしたのを覚えています。OCamlでもけっこうきついのに、よくVerilogで書けるなあ、と……
スケジューラは(よっぽど変なことをしない限り)命令の優先順位がおかしくても動きはしてしまうため、バグの存在が見えにくいです。実際、実装した時点では40秒のうちの2秒くらいしか変わりませんでした。しかし、コア係に指摘してもらったバグの修正や実装の改善点を取り入れてみたり*9などを2月上旬まで続けていった結果、最終的に20%も実行時間が減っていました。
試験終わりまで(1月)
このあたりで、計算量理論演習や知能システム論の課題がだいぶきつくなってきました。それが終わると試験のための準備が必要になり、CPU実験に回せるリソースが多くなくなってしまいました。
命令スケジューリングの実装も終わり、いよいよやることが見つけにくくなっていた時期でもありました。この時期実装した新しい最適化は連鎖するジャンプの除去くらいでした。それ以外ではもっぱら既存の最適化(論理最適化、共通部分式削除、タプル平坦化)の強化を進めていました。
びっくりしたのが、このあたりでインライン展開を、再帰関数以外はすべて展開するようにしたところ、もともと17億命令だったのが15億命令にまで減りました。2億命令も減ってびっくりしました。
最後の追い込み(~2/15)
ワードアドレッシング
2月に入ったくらいで班全体としてワードアドレッシングへの移行が完了しました。これにより、0.8億命令くらい削減できました。
グローバルレジスタ割り当て
この直後くらいにグローバルレジスタ割り当てが完成し、命令数が13億まで減りました。
関数呼び出しの依存グラフがDAG(つまり相互再帰がない)で、かつminrtの場合クロージャがない(どこに飛ぶかがわかっている)ため、末端の関数から順に「その関数が使うレジスタ」を確定させることができます。すると、レジスタ割り当ての時、関数呼び出し先で使わないレジスタに対して優先的にallocateすることが可能となります。このようなレジスタは関数呼び出し時に破壊されないため退避する必要がなく、結果として関数呼び出しに伴うload/store(スタックアクセス)を60%減らすことに成功しました。残りの40%はおそらくレジスタが足りなかったことによるもので、スタックアクセスは6500万回ほど残ってしまいました。
fabsとfneg
この後しばらくは命令スケジューリングのバグ取りに奔走することになりました。さらに、絶対値を取るとき
fblt f0, f1, LABEL
fsub f1, f0, f1
jal CONT
LABEL:
CONT:
...
みたいな超無駄なことをしていたので、fabs(とついでにfneg)の実装を依頼しました。さらに、直後に飛ぶジャンプ命令の除去を実装しました。これにより12.6億命令まで減らすことができました。このとき2/11でした。
トレーススケジューリング
とうとうやることが見つからなくなり、コンパイラの本を眺めていると、「トレーススケジューリング」なる手法があることがわかりました。ちょうど、スーパースカラなのにIPCが0.7しか出ず、なんじゃこりゃと思っていたので、最後の大仕事としてトレーススケジューリングの実装をすることに決めました。
しかし、この時点で残り3日だったのと、そもそもあまり文献がなくて実装に相当苦労しました。この文献がわかりやすかったので、これを読みつつ実装を進めていました。スケジューリングの宿命として、しょうもないけど非自明なバグに苦しめられました。発表会当日の朝に投機的スケジューラという形でかろうじて部分的に完成したものの、実行時間は0.2s減、IPCは0.75にしかならず、力不足を感じました。
結果
最終結果は、命令数12.6億、実行時間14.5秒でいずれも2位となりました。1位の班はアーキテクチャをかなり工夫していたようです。結果として出てしまうとどうしても悔しいですね。
この半年間相当の労力を注ぎ込んできたので、終わったときはなんともいえない虚脱感でした。部活の引退試合ってこんな感じなのかな、などと思いました。
謝辞
最後になりましたが、プロセッサ・コンパイラ実験担当の先生方、TAの方々、そして何より4班の班員に感謝を申し上げたいと思います。ありがとうございました。
*1:なお今年は担当の先生により「FPU係の単位要件にキャッシュメモリの作成が追加」「シミュレータ係の単位要件に実行時間予測が追加」というコンテンツが追加されました
*2:MLのサブセット
*3:今年は各回「個人課題」に加え「グループ課題の提出」が単位要件でした。グループ課題は先生の意図としては分担してやってほしかったようですが、うちの班ではコンパイラ係が全てやってしまいました……。その分他の係は自分のすべきことに集中するということで…
*4:ざっくりいうとオブジェクトと光源とカメラの位置から3D画像を生成すること
*5:たとえば add f1, f1, f2 みたいなコードが生成されていると、「レジスタの指定が間違っています!」というエラーを出してくれていました。この機能も本当にありがたかった…
*6:まあ配列への書き込みという副作用は実際あるんですが、共通部分式削除に関しては、一度fを呼んだあとは、違う値をarrに書き込むまではfは副作用がないとみなせます
*7:この時期に睡眠習慣が崩壊してしまい進捗を生めなかったのもあるのですが…
*8:MinCamlデフォルトではすべてcaller saveなので、うまいことやれば改善できる余地はあります。ちなみにグローバルレジスタ割り当てを導入するとこの問題が消えます。
*9:命令が逆順にスケジューリングされていたのを修正したり、依存グラフにおいてRAW依存以外のときはレイテンシ(≒優先度)を加算しないようにしたり。本当によくあのスパゲティコードを読んでくれたなということで感謝しかないです
再帰関数をwhileループに変換する
動機
GLSLで
vec3 shade(...){ if(material == glass){ R * shade(reflection) + (1-R) * shade(refraction); } }
みたいなシェーダを書こうとして、「あれ、GLSLで再帰関数って書けないの……?」となり、whileで書く方法を調べていたところ、上のような関数呼び出しの後でいろいろ処理して値を返すような一般の関数に直接応用できる手法をなかなか見つけられず、さらにいろいろ調べたところ、コールスタックっぽいことをするとうまくいくようなので、書いてみようと思いました。
コールスタック及び呼び出し規約周りの知識があるとより分かりやすいかもしれません。
この投稿(英語)がかなりわかりやすいですが、本稿では複数の再帰を持つ、より一般的な例を扱っています。
前処理
①変換元
似たようなプログラムをpythonで書きました。
def f(x): if x == 0: return 1 elif x == 1: return 2 * f(x-1) + f(-(x-1)) else: return 2 * f(x+1) * f(-(x-1))
②まずreturn hoge を ans = hoge; return ans にします。
def f(x): if x == 0: ans = 1 return ans elif x == 1: ans = 2 * f(x-1) + f(-(x-1)) return ans else: ans = 2 * f(x+1) * f(-(x-1)) return ans
③次に関数呼び出し部を独立させます。
(コンパイラの中間表現を知っている方は ret = Call(f, x) をイメージするとわかりやすいかもしれません)
def f(x): if x == 0: ans = 1 return ans elif x > 0: ret1 = f(x-1) ans = 2 * ret1 ret2 = f(-(x-1)) ans += ret2 return ans else: ret1 = f(x+1) ans = 2 * ret1 ret2 = f(-(x+1)) ans += ret2 return ans
④エントリーポイントにラベルL0を、それ以降の関数呼び出し地点の直後に順にL1, L2, ...をつけます:
def f(x): #L0 if x == 0: ans = 1 return ans elif x > 0: ret1 = f(x-1) #L1 ans = 2 * ret1 ret2 = f(-(x-1)) #L2 ans += ret2 return ans else: ret1 = f(x+1) #L3 ans = 2 * ret1 ret2 = f(-(x+1)) #L4 ans += ret2 return ans
⑤これをgoto文に書き換えて、基本ブロックを独立させます:
def f(x): #L0 if x == 0: ans = 1 return ans elif x > 0: ret1 = f(x-1) goto L1 else: ret1 = f(x+1) goto L2 #L1 ans = 2 * ret1 ret2 = f(-(x-1)) goto L2 #L2 ans += ret2 return ans #L3 ans = 2 * ret1 ret2 = f(-(x+1)) #L4 ans += ret2 return ans
⑥gotoをwhileに書き換えます。returnはまだそのままにします。
pc という、「現在プログラム中のどの部分を処理しているか」の状態を表す変数で管理しています。
def f(x): pc = 0 # program counter while(True): if(pc == 0): #L0 if x == 0: ans = 1 return ans elif x > 0: ret1 = f(x-1) pc = 1 else: ret1 = f(x+1) pc = 1 elif (pc == 1): #L1 ans = 2 * ret1 ret2 = f(-(x-1)) pc = 2 elif (pc == 2): #L2 ans += ret2 return ans elif (pc == 3): #L3 ans = 2 * ret1 ret2 = f(-(x+1)) pc = 4 else: #L4 ans += ret2 return ans
メイン処理
ここからが本番です。return とは「元の関数呼び出し文脈へのreturn」ですが、どうやってreturnするんやという問題を解決しなければなりません。
これを、コールスタック的な概念を導入することで解決します。アセンブリというかCPUの処理を模倣するようなイメージです。
ざっくりいうと、
- 前の関数呼び出しの結果を格納する変数
retを用意する。 - 関数呼び出しのときは
- スタックに、次に飛びたいラベルの番号、及び現在の(生きている)変数の値たちを積む。
- 設計上は「どこかの関数呼び出し地点の前後で生きていうる変数すべて」としたほうがシンプルなので、その方針にします。
- そのうえで関数引数をセットして、
- pcを0にする(+while文の先頭に戻る)ことで「関数呼び出し」が成立する。
- スタックに、次に飛びたいラベルの番号、及び現在の(生きている)変数の値たちを積む。
returnは- retに返したい値を代入する。
- スタックがあるなら、
- 呼び出し元で飛びたいと思っていたラベルの番号、及び呼び出し元での変数の値をスタックから取り出す。
- pc及び変数の値をセットすることで、元の「関数呼び出し文脈」に帰れる。
- スタックがないなら、
return retすることで、"大元の関数fの値を返す"ようにする。
初めに「生きていうる変数」の一覧を作ります。④を見ると、xに加えansも生きている変数になりうることがわかります。
まずL0の関数呼び出しret1 = f(x-1); pc = 1を変換します。上の手順に従うと、
stack.append([1, x, ans]) x = x - 1 pc = 0
次にL2のans += ret2; return ansを変換します:
ans += ret ret = ans if len(stack) == 0: return ans else: pc, x, ans = stack.pop()
同様に変換すれば、次のような⑦最終形が得られます:
def g(x): ans = 0 # temporary variable ret = 0 # return value pc = 0 # program counter stack = [] stack.append([pc, x, ans]) while(True): if(pc == 0): if(x == 0): ret = 1 if len(stack) == 0: return ret else: pc, x, ans = stack.pop() elif(x > 0): stack.append([1, x, ans]) x = x - 1 pc = 0 else: stack.append([3, x, ans]) x = x + 1 pc = 0 elif pc == 1: ans = 2 * ret stack.append([2, x, ans]) x = -(x - 1) pc = 0 elif pc == 2: ans += ret ret = ans if len(stack) == 0: return ret else: pc, x, ans = stack.pop() elif pc == 3: ans = 2 * ret stack.append([4, x, ans]) x = -(x + 1) pc = 0 elif pc == 4: ans += ret ret = ans if len(stack) == 0: return ret else: pc, x, ans = stack.pop()
ひょっとすると、①→③→④→⑦くらいに飛ばすほうがわかりやすいかもしれません。
これを使うと相互再帰も同様の手順で書けると思われます。
自動変換するプログラムとか書けそう。
余談
なお、もう少し厳密に「呼び出し規約」を書き下すと、次のようになります:
- 「スタック」を用意する。プログラム中では
リストで実装している。 - 「レジスタ」をいくつか用意する。これはプログラム中では
変数である。 - 「関数呼び出し」(
ret1 = f(x-1)等)の手順は次の通り。- 「リターンアドレス」と「今生きている変数」
x,ansを「スタック」に積んでおく。- 「リターンアドレス」は、次に向かうべき
ラベルになる。
- 「リターンアドレス」は、次に向かうべき
- 「引数」を引数格納用レジスタ
xに入れる。 - 「呼び出し」を行うため「プログラムカウンタ」を関数の先頭にセットする。
- 「リターンアドレス」と「今生きている変数」
- 値を返す(returnのとき)ときは、
なので、本当は関数呼び出しの時点で、引数レジスタにあるxの値をcallee saveな汎用レジスタに移しておかなければならないのだろうけれど、それをすると余計ややこしくなりそう…
Schemeの式をEmacsで簡単に実行する
この記事は、ISer Advent Calendar 2021の21日目の記事です。前日の記事はfushiguさんによる「噂のCPU実験」でした。翌日の記事は81uemanさんによる「ノルムで遊ぼ」です。
この記事では、SchemeやOCamlの式を簡単に実行するためのEmacsの設定を書き残しておきます。なお、SchemeやOCamlを書くことになったのは、学科の実験(プログラミング課題)のためなので、そのことが前提となっています。
なぜEmacsか
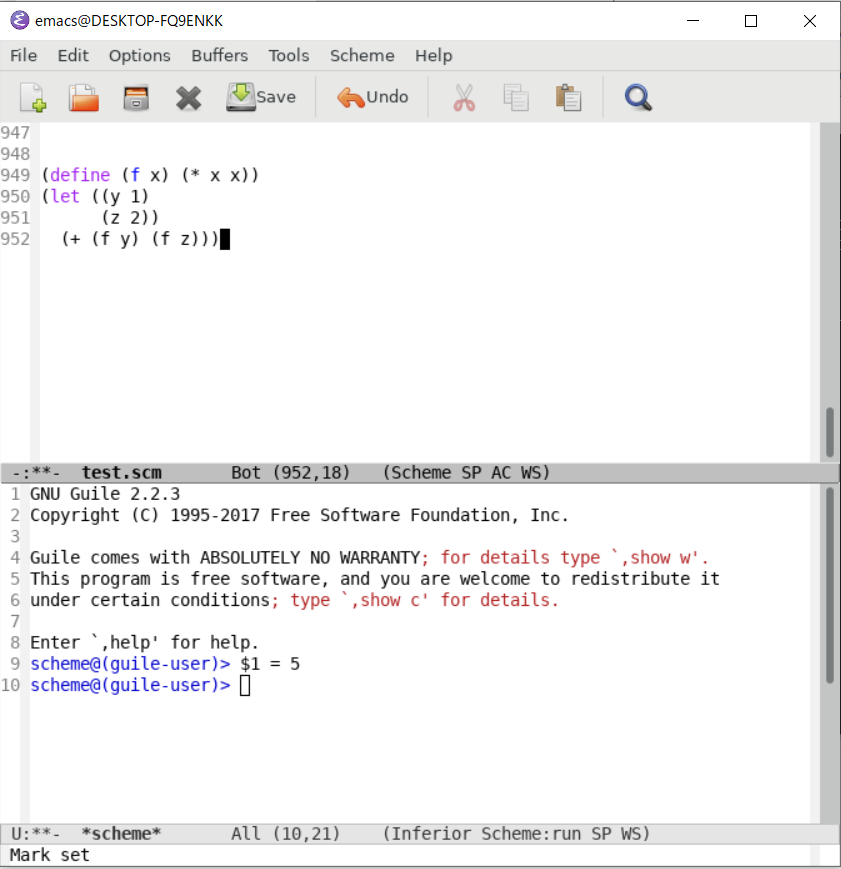
VS Codeで書いてもいいんですが、2Aの実験のサイト*1で、Emacsを使うための設定が書かれているため、とりあえずEmacsを使うか~となりました。
使ってみると、いろいろカスタマイズができることがわかりました。こんな感じで、キーボードショートカット一つで、1画面で結果が表示されるようにできました。
Scheme on Scheme*2までたどり着けたのも、これがあったからかもしれません。
特に、Schemeの課題の大部分やOCaml課題*3の前半は「フィボナッチ数列の第n項を求める関数fibを定義せよ。」のような小さな関数一発であることが多いので、毎回コンパイルするよりも、ショートカット一発でできるこちらのほうが楽でした。*4
この手法の限界
ただし、Scheme on Schemeのように、大量の関数を定義するような大きいファイルは、毎回実行のショートカットを連打するよりも、素直にターミナルでコンパイルしたほうが早いかもしれません*5。そのうえ、Emacs上のScheme処理系は重いので、guileだと動くはずのScheme on Scheme on Schemeが動かなくなった気がします。
それに、VS Codeのほうが大量のファイルを管理するのは楽なので*6、それが求められる場面(OCaml課題の後半のOCaml処理系作成、など)ではVS Codeのほうがいいかもしれません。(僕は3SまではEmacs + ターミナル + Makefileで頑張りましたが、3Aのコンパイラ実験でVS Codeを使い始めました。)
環境
Win10に乗っているWSL1です。 このサイトとかが参考になると思います。 GUI(X Server)を動かすのに苦労した記憶があるんですが、なぜだか具体的な手順を覚えていないです。~/.bashrcに
export DISPLAY=:0.0 export PATH=~/anaconda3/bin:$PATH
という文言があることだけは確かです。
前提知識
Emacs教習所にお世話になりました。ここのinit.elの設定は、undo-treeと見た目の変更、multi-term以外はやりました。(undo-treeは入れたかったんですが、なぜか激重になったので諦めました……) また、実験のサイトの設定も追加しました。
本題
ただ、実験のサイトの設定だけだと、ターミナルがEmacsの画面上で開くのみです。
そこからさらに一歩進めて、「今開いている.scmファイルの、カーソルの位置の式 *7 を、キー操作一つで開いたターミナルに打ち込める」ことができれば便利です。発想としては、C-c C-eで使える(eval-last-sexp)に近いですが、もっと便利です。
挙動をもう少し詳しく説明しておくと、
- C-c C-j で、現在のカーソルの位置の式を処理系に打ち込む。
- このとき、現在Scheme処理系が立ち上がっていないならば、自動的に開く。*8
- このとき、現在Scheme処理系が立ち上がっているもののそのウィンドウが開かれていないならば、そのウィンドウを自動的に開く。
みたいな処理をします。
それを実現するために、init.elに次のようなコードを書きました。*9
かなりガバガバなコードな気がします。怒らないでください。
(defun my-execute-scheme () (interactive) (if (string= mode-name "Scheme") (progn (run-scheme scheme-program-name) (end-of-buffer) (other-window -1) (scheme-send-last-sexp)) ) ) (add-hook 'scheme-mode-hook '(lambda () (define-key scheme-mode-map (kbd "C-c C-j") 'my-execute-scheme))) (defun my-execute-scheme-all () (interactive) (if (string= mode-name "Scheme") (progn (run-scheme scheme-program-name) (end-of-buffer) (other-window -1) (scheme-load-file (buffer-file-name (current-buffer)))))) ;;(global-set-key (kbd "C-c C-a") 'my-execute-scheme-all) (add-hook 'scheme-mode-hook '(lambda () (define-key scheme-mode-map (kbd "C-c C-a") 'my-execute-scheme-all)))
とりあえず、Emacsで適当に.scmファイルを開き、適当に任意の式を書いて、任意の式の後ろでC-c C-j *10してみると挙動がわかると思います。
解説
(interactive)
コマンドを書くためには、関数の最初にこれを入れることが必要らしいです。
(if (string= mode-name "Scheme")
「もし現在のモード名が"Scheme"なら」。Scheme以外の言語でSchemeの処理系が開かれると困ります。*11
(progn (run-scheme scheme-program-name) (end-of-buffer) (other-window -1) (scheme-send-last-sexp))
⓪現時点では、フォーカスは.scmファイルを編集しているウィンドウ(以下「編集ウィンドウ」)にあるはずである。
① (run-scheme)でschemeを起動する。このとき、(defadvice run-scheme ...)の影響で、最終的には「編集ウィンドウとguileが走っているウィンドウの二つがあり、後者にフォーカスがある」状態になる。*12
②よってこのバッファの最下部に飛んでから、
③編集ウィンドウに戻り、
④「カーソルの位置の式」をguileに送る。
すると評価結果が表示されます。
(add-hook 'scheme-mode-hook '(lambda () (define-key scheme-mode-map (kbd "C-c C-j") 'my-execute-scheme)))
scheme-modeを起動するときに、"C-c C-j"を上述の関数に割り当てます。
my-execute-scheme-all も似たようなことをやっています。
ちなみに、OCaml・Prolog ver は以下の通りです。やってることはだいたい同じです。
;; https://y0m0r.hateblo.jp/entry/20130524/1369405033 から4行 (defun my-execute-ocaml () (interactive) (if (string= mode-name "Tuareg") (progn (tuareg-run-process-if-needed tuareg-interactive-program) (if (not (string= mode-name "Tuareg")) (other-window -1)) (tuareg-eval-phrase) ))) (add-hook 'tuareg-mode-hook '(lambda () (define-key tuareg-mode-map (kbd "C-c C-j") 'my-execute-ocaml))) (autoload 'prolog-mode "prolog" "Major mode for editing Prolog programs." t) (add-to-list 'auto-mode-alist '("\\.pl\\'" . prolog-mode)) (defun my-prolog-consult-file () (interactive) (if (string= mode-name "Prolog") (progn (run-prolog t) (prolog-consult-file) (other-window -1)))) (defun my-prolog-query-clause () (interactive) (if (string= mode-name "Prolog") (let* ((send-string (progn (prolog-mark-clause) (buffer-substring-no-properties (region-beginning) (region-end))))) (progn (if (eq (get-process "prolog") nil) (my-prolog-consult-file)) (run-prolog) (end-of-buffer) (insert send-string "\n")) ) ) ) (add-hook 'prolog-mode-hook '(lambda () (define-key prolog-mode-map (kbd "C-c C-j") 'my-prolog-query-clause))) (add-hook 'prolog-mode-hook '(lambda () (define-key prolog-mode-map (kbd "C-c C-k") 'my-prolog-consult-file)))
おまけ
init.elのその他の設定のうち、自分が書いた部分のみ載せておきます。Emacs教習所にいろいろ載っています(再掲)。
smartparens
これがあるとカッコが自動で補完されて、いい感じになります。
(leaf smartparens :require smartparens-config :ensure t :custom ((smartparens-global-mode . t)) )
ウィンドウの大きさの初期値を変える
デフォルトだと10行くらいしかなく、縦に狭いので、こうすると広げられます。
(add-to-list 'initial-frame-alist '(height . 35)) (add-to-list 'default-frame-alist '(height . 35))
余談
- 一度init.elを書くと、init.elさえ移せば他の環境でも同じ環境が簡単に再現できるのがEmacsの魅力です。具体的には、私物のPCから学科PCの仮想環境への移行がスムーズでした。ここまでの設定をすればCのコードもそこそこ書きやすくなっているはずです。*13 2021年度以降は、ASMでリモートアクセスすることになるECCSの環境にも適応してくれると思います。*14
- 最終的にはいろいろ書いたので、単にコピペするだけじゃなくて、他の人の書いたinit.elを解読したりelispのドキュメントを読んだりEmacsでdescribe-variableしたりして、自分なりにelispによるinit.elの書き方を勉強することができました。
- elispは、Schemeと同じくLispの方言らしいです。なので、動かねえ~~~って言いながらelispのドキュメントを読んでる間、なんでLispの方言(Scheme)を学ぶためにLispの方言(elisp)を学んでるんだろう、という気持ちになりました。勉強になってよかったです。
*1:2021/12/21現在、「情報科学基礎実験」でググるとこのサイトが出てくるので、これは公開情報のはずです
*2:Schemeで、自分自身を読み込めるScheme処理系を書いてみよう!という、Schemeの課題の最終目標です。
*4:Q. Code Runnerか何か入れればいいんじゃないですか? A.それでもいいんですが、Windows上にguileを入れるにしてもCode Runnerと連携させるのがよくわからず、WSL上でやるにしてもVS CodeをWSLと連携させる方法が当時よくわかりませんでした…(3Aで学科の人に手伝ってもらいながらやっとできたので、今でもよくわかっていないです)
*5:いちおうC-c C-aで全実行できるようにはしていますが…
*6:VS Codeでは、常に画面上にファイル一覧が表示されていて、GUIでそれを並べ替えたり、クリックで編集するファイルを切り替えられたりするのが非常に便利です。Emacsでもそれを実現する方法はあるかもしれませんが…あと、Emacs、ウィンドウ名が全部emacs@DESKTOP-...なんですよね。これが致命的でした。
*7:関数型言語だと、C言語における int a = 1; のような命令も、すべて「式」と呼ばれます。例えば、Schemeだとこれと等価な式は (define a 1) となります。この式を処理系に打ち込むと、「aが1である」という定義を現在の処理系で行うことができます。
*8:なお、複数ウィンドウ開いていると、現在のウィンドウの次のウィンドウが勝手にScheme処理系に移ってしまうようです。
*9:この記事のコードの著作権は放棄しますが、使うときは自己責任でお使いください。
*10: jikkou のj。あと、C-c C-eだと両方左手で使いにくかったため。
*11: (add-hook 'scheme-mode-hook ...)してるから不要っちゃ不要ですが、一応の保険です。これを書いた当時 ;;(global-set-key (kbd "C-c C-j") 'my-execute-scheme) みたいなマネをしてた名残でもあります。
*12:編集ウィンドウのみでもすでにguileのウィンドウが開いていても、まだguileが走っていなくとももうguileが走っていてもOKです。このへんについては、Scheme-mode で C-h f run-scheme したら出てくるヘルプと (defadvice) を眺めてください。
*13:2Aでは自分のPCでコードを書くことになると思います。3Sからは学科PCが学科から配布されます。このinit.elは、2Aのとき、自分のPCのEmacsのために書いたものでしたが、それをそのまま、3Sにおいて学科PCのHyper-Vで動かすUbuntuに輸入しました。
*14:2020年度ではECCSのEmacsはver22とかだったと思います。そのせいでleafが使えず、whitespaceもautocompleteもsmartparensも読み込めなかったため、泣きながら手元のVS Codeで書いたアセンブリコードをコピペしていました。